
El informe definitivo que nadie va a verificar pero todos compartirán 🎉
«Si suena a número y lleva un % al lado, debe de ser cierto» — Algún gurú en LinkedIn, 2025
Continúa leyendo «El 124 % de las estadísticas online son puro cuento»

«Si suena a número y lleva un % al lado, debe de ser cierto» — Algún gurú en LinkedIn, 2025
Continúa leyendo «El 124 % de las estadísticas online son puro cuento»
El lenguaje de programación R es una de las herramientas más utilizadas para análisis estadísticos y la creación de gráficos debido a su capacidad para manejar grandes conjuntos de datos y su amplia variedad de paquetes para visualización, como ggplot2. Sin embargo, no es la única opción disponible para quienes buscan hacer gráficos estadísticos. A continuación, te presento algunas alternativas a R que también son robustas y versátiles para la creación de gráficos estadísticos.
Continúa leyendo «Alternativas a R para hacer gráficos estadísticos»
Varias veces os he explicado cómo funciona ChatGPT, os he comentado el sistema de estadísticas de los modelos de IA generativa y el cómo vomita palabras con sentido en función de las frases con las que ha sido entrenado.
El caso es que hay una página que muestra de forma gráfica todo esto.
Continúa leyendo «Una página que muestra por qué ChatGPT funciona como funciona»
Es probable que pocos hayan oído hablar de la paradoja del cumpleaños. Esta hace referencia a un planteamiento matemático el cual establece que dentro de un conjunto de 23 personas la probabilidad de que dos de estas cumplan años el mismo día es de 50,7%.
Este porcentaje tiende a ser mayor en la medida que el número de personas es mayor, llegando a ser prácticamente del 100% en el caso de un grupo formado por 365 o 366 personas (tomando en cuenta si es un año bisiesto).
Continúa leyendo «Conoce esta página web que simula la paradoja del cumpleaños»
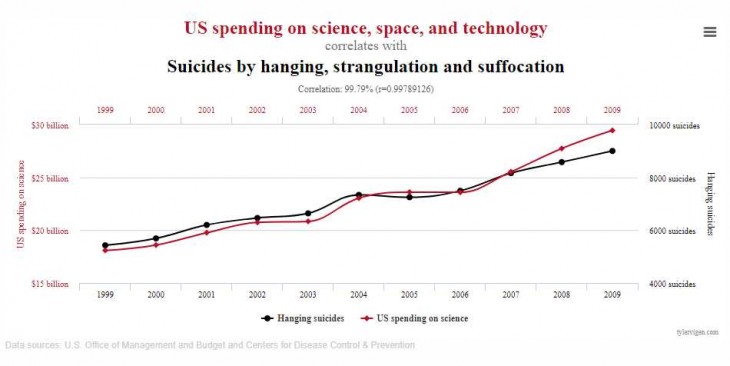
Analizar el gráfico de evolución con los años de determinados eventos es una actividad que puede resultar muy interesante y educativa para muchos. Podemos ver la cantidad de accidentes de coche en un país específico cada año, o la cantidad de películas realizadas por un actor determinado… podemos analizar prácticamente todo, y además podemos comparar los gráficos entre ellos. Continúa leyendo «Una web para reírse de algunas estadísticas»

Yahoo Finance, uno de los referentes mundiales en lo que a noticias, artículos especializados, análisis, datos históricos e información en tiempo real de los mercados financieros se refiere, ha renovado la interfaz de su sitio web para hacer más cómoda y personal la distribución de dichos contenidos junto a los seguimientos y análisis que cada usuario puede permitirse con ayuda de las herramientas proporcionadas por el servicio. Continúa leyendo «El nuevo diseño de Yahoo Finance: más personal e interactivo»
Si sois usuarios de Buffer, la herramienta que nos permite enviar y programar publicaciones a varias redes sociales al mismo tiempo, a partir de ahora podréis disfrutar de un nuevo módulo de estadísticas ideal para saber, por ejemplo, cuáles han sido las publicaciones con más éxito de las últimas enviadas.

Solo tenemos que pulsar en este enlace para ver lo que ofrecen, disponible tanto para cuentas awesome como para cuentas business. Como veis en la captura, es posible filtrar por varias variables, obteniendo información sobre los posts que reciben más clicks o que fueron más marcados como «favoritos», por ejemplo.
Podemos también hacer lo contrario, ver los posts que no han tenido ninguna repercusión, ayudando así a determinar lo menos popular entre nuestros lectores.
En el informe podemos mostrar el formato del post publicado, ayudando también a determinar si las imágenes tienen más éxito que los textos, por ejemplo, algo que muchos analizamos constantemente. Este filtro puede combinarse con los anteriores, obteniendo listas como «los tweets con imágenes que más veces han sido retuiteados».
Por supuesto, es posible elegir la fecha de análisis, y podemos exportar los datos para analizarlos con calma fuera de la aplicación.
Una fantástica nueva funcionalidad que ayudará mucho a los que trabajamos con información en redes sociales.
 En vidooly.com tenemos un proyecto que, sin necesidad de registro, nos permite obtener estadísticas básicas sobre cualquier canal de youtube.
En vidooly.com tenemos un proyecto que, sin necesidad de registro, nos permite obtener estadísticas básicas sobre cualquier canal de youtube.
Solo tenemos que indicar el nombre del canal que queremos analizar y ver datos como los vídeos más vistos de todos (en la imagen izquierda tenéis los más populares del canal youtube.com/wwwhatsnew), el crecimiento de usuarios, la previsión de crecimiento (hace una media de número de usuarios y tiempo de existencia, por lo que no utiliza ningún sistema extremadamente inteligente), los seguidores con más influencia, las ganancias estimadas, los canales relacionados… datos que se irán guardando para que se muestre un histórico después de un tiempo (no mostrará mucha información si es la primera vez que se analiza).
Aunque en este tipo de proyectos siempre es importante coger la información con pinzas, puede ayudar a conocer la magnitud de un canal que nos interese, así como comparar varios y verificar el interés que despierta entre su comunidad.
En el menú superior tenemos acceso a un ranking y a los vídeos que más están creciendo en este momento, semejante a lo que ya hace youtube con su proyecto www.youtube.com/trendsdashboard
Si queréis saber si existe alguna relación entre el consumo de queso y el número de divorcios, o entre los peatones atropellados por trenes y el número de abogados, tylervigen.com es vuestro sitio web ideal, presentado hace pocas horas en theverge.
Se trata de una aplicación en la que podemos seleccionar decenas de variables y buscar su correlación con otras muchas, encontrando semejanzas que pueden servir de inspiración para las más disparatadas teorías.
Son datos reales obtenidos de fuentes fiables que, guardados en una base de datos, sirven como alimento para que cada usuario pueda realizar gráficos de su evolución durante los últimos años. En la página principal tenemos algunas de las relaciones más extrañas, aunque pulsando en «encuentra una nueva correlación» podemos jugar con las variables que deseemos.

Al crear una nueva relación podemos seleccionar la categoría original y esperar a que muestre las variables relacionadas. La segunda categoría estará directamente relacionada con la primera, por lo que siempre veremos gráficos con una correlación alta.
Ideal para crear temas de discusión para un domingo por la noche.
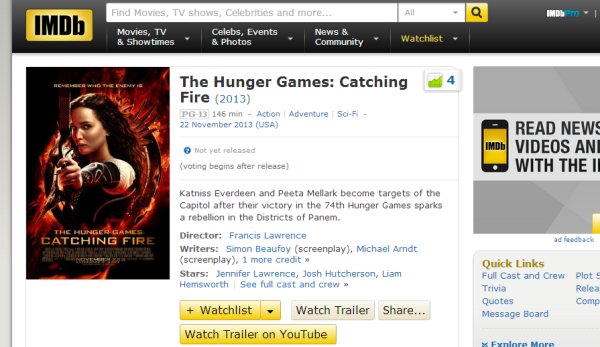
Si eres un fanático del cine seguramente alguna vez habrás oído o leído sobre IMDb, the internet movie database, un completo portal con información y contenido multimedia (imágenes, videos, estadísticas, etc.) sobre películas, TV y artistas de todo el mundo.
Algo incómodo con el material multimedia que es gestionado en el portal es que es mostrado con reproductores propios que le hacen parecer bastante limitado si se compara a opciones como Dailymotion o YouTube. Es entendible que lo hagan para tratar de combatir las copias ilegales pero un tráiler el único efecto que consigue es ganar aun más seguidores así que no es algo aceptable, se debe buscar una solución que facilite la experiencia.
En fin, para esto ha sido creada IMDB Watch Trailer on YouTube, una extensión para Google Chrome que no reemplazará los trailers incrustados en IMDB sino que permitirá revisar los mismos tráilers en YouTube con apenas dar un clic sobre Watch trailer on YouTube, un nuevo icono que aparecerá junto a los de siempre: Watchlist y WatchLater.
Seguramente aparecerá en inglés el video resultante, pero ya en YouTube será posible activar los subtítulos o valerse de los videos recomendados para encontrar resultados en el idioma preferido.
Enlace: IMDB Watch Trailer on YouTube en la Chrome Web Store


