
¿Alguna vez te has preguntado cómo las máquinas aprenden a realizar tareas? ¿Cómo los algoritmos de recomendación pueden saber qué productos sugerirte sin siquiera preguntarte directamente? Bueno, esto se debe al aprendizaje por refuerzo, un tipo de aprendizaje automático que utiliza recompensas para guiar a los modelos hacia comportamientos valiosos. Pero, ¿cómo se definen estas recompensas? ¿Y qué pasa cuando las recompensas no son explícitas o no se pueden medir fácilmente?
Este es el problema que aborda la investigación presentada en la Conferencia Internacional sobre Representaciones de Aprendizaje (ICLR) de 2023, que propone un enfoque novedoso para el aprendizaje por recompensa inferida. En lugar de depender de recompensas explícitas, el enfoque llamado Aprendizaje basado en la interacción (IGL) permite a los modelos inferir recompensas latentes a través de la interacción con el entorno y los usuarios.
Aprendizaje por refuerzo y la complejidad de definir recompensas
Antes de profundizar en el enfoque de IGL, es importante comprender el concepto de aprendizaje por refuerzo. En el aprendizaje por refuerzo, un agente (un modelo) aprende a realizar una tarea al interactuar con un entorno y recibir recompensas (o castigos) por sus acciones. El agente aprende a maximizar la recompensa total a lo largo del tiempo, lo que significa que aprende a realizar acciones que lo lleven a obtener recompensas más valiosas.
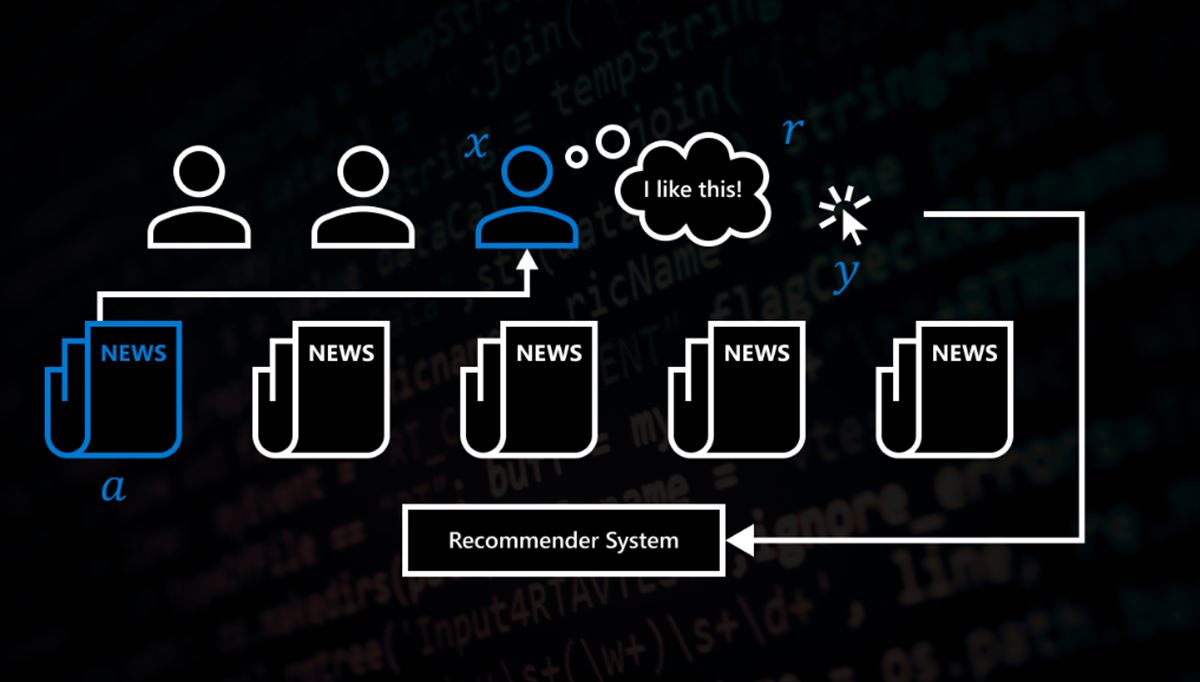
Sin embargo, la definición de recompensas puede ser muy compleja. Por ejemplo, en un sistema de recomendación, ¿cómo se define la recompensa? ¿Es simplemente el hecho de que un usuario haga clic en un producto sugerido? ¿O debería tener en cuenta factores como la satisfacción a largo plazo del usuario con el producto? ¿Cómo se define y se mide la satisfacción a largo plazo? Estas son preguntas difíciles de responder, y la complejidad solo aumenta cuando hay diferencias en cómo los usuarios interactúan con el sistema.
Aprendizaje basado en la interacción (IGL)
Aquí es donde entra el enfoque de IGL. En lugar de depender de recompensas explícitas, IGL utiliza señales de retroalimentación más sutiles, como los clics de los usuarios, para inferir una recompensa latente. Esta recompensa no es observable directamente, pero se puede inferir a partir de las señales de retroalimentación.
El enfoque de IGL propuesto en la investigación presentada en ICLR 2023 es IGL-P, que es el primer enfoque de IGL para retroalimentación dependiente del contexto, la primera vez que se utiliza la cinemática inversa como objetivo de IGL y la primera vez que se utiliza el enfoque IGL para más de dos estados latentes. IGL-P aprende a maximizar esta recompensa latente a través de la interacción con el entorno y los usuarios, lo que permite una personalización más efectiva de la experiencia del usuario.
IGL
El enfoque de IGL es particularmente útil para aplicaciones de aprendizaje interactivo, como los sistemas de recomendación. Los sistemas de recomendación se utilizan para proporcionar sugerencias de contenido personalizadas a los usuarios en función de su historial de interacciones. Sin embargo, es difícil definir una recompensa explícita para los sistemas de recomendación. Por lo tanto, los sistemas de recomendación modernos utilizan señales implícitas de retroalimentación, como los clics de los usuarios, para inferir si un usuario está satisfecho con la recomendación.
Sin embargo, estas señales implícitas no siempre son una medida precisa de la satisfacción del usuario. Por ejemplo, un usuario podría hacer clic en un artículo solo porque el titular es sensacionalista, pero luego descubrir que el contenido no es relevante o de calidad. Esto podría llevar a una experiencia de usuario insatisfactoria y dañar la reputación del sistema de recomendación.
IGL-P
IGL-P proporciona una solución escalable y efectiva para el aprendizaje personalizado de agentes, lo que puede mejorar significativamente la experiencia del usuario. IGL-P aprende funciones de recompensa personalizadas para diferentes usuarios en lugar de depender de una función de recompensa fija y diseñada por humanos. Aprende a partir de señales de retroalimentación variadas y utiliza la cinemática inversa para inferir la recompensa latente subyacente.
La efectividad de IGL-P se demostró en experimentos que utilizan simulaciones y trazas de producción del mundo real. Los resultados mostraron que IGL-P puede aprender a distinguir entre diferentes modalidades de comunicación de los usuarios, y puede mejorar significativamente la eficacia de los sistemas de recomendación al aprender a maximizar la recompensa latente subyacente. IGL-P también se demostró que supera a los métodos de aprendizaje de agentes personalizados actuales que requieren una calibración de parámetros de alta dimensionalidad, recompensas diseñadas por humanos o estudios de usuarios extensos y costosos.
La investigación presentada en ICLR 2023 destaca la importancia del aprendizaje por refuerzo en el aprendizaje automático, así como la complejidad de definir recompensas. La utilización del enfoque de IGL proporciona una solución efectiva para el aprendizaje personalizado de agentes en aplicaciones de aprendizaje interactivo, como los sistemas de recomendación. IGL-P representa una mejora significativa en los métodos actuales de aprendizaje de agentes personalizados, lo que puede mejorar significativamente la experiencia del usuario.