Presentándose como un robot inteligente capaz de reconocer cualquier música que le enviemos, Audiotag.info muestra el título y autor de los archivos musicales que de los que no sabemos nada.
Sólo tenemos que subir el archivo o indicar la dirección en la que se encuentra. 15 segundos de la música son suficientes para que audiotag reconozca la música y muestre toda la información que es capaz de recopilar después de su análisis.
Compatible con vídeos de youtube es una buena alternativa (más sencilla de usar) que la ya comentada musipedia.
Reconocer los textos escritos en una imagen y poder importarlos en un documento para editarlos no es tarea fácil. Depende mucho del idioma, de la calidad de la imagen, del tipo de fuente utilizada y, por supuesto, del programa de reconocimiento (OCR – Optical Character Recognition) que esté siendo usado.
Aquí os dejo tres opciones que podéis probar en Internet para reconocer los caracteres de cualquier imagen, facilitando, aunque sea un poco, el trabajo de escribir a mano su contenido.
Permite obtener el texto de cualquier imagen en formato JPG, GIF, TIFF, BMP o PNG o documento PDF, reconociendo varios idiomas, español incluido. Las imágenes no pueden ser mayores de 2 megas y tampoco podréis procesar más de 10 páginas por hora. No es necesario el registro, tan solo piden una dirección de email.
Reconocimiento en 28 idiomas de manera automática, con un tamaño máximo de un mega por archivo.
Actualización: Prestemos también atención al código que Google nos ofrece en googlecodesamples.com/docs/php/ocr.php, importando directamente el resultado en Google Docs.
Google Lens
Podéis usar Google Lens para capturar un documento y extraer su texto, directamente desde el móvil, lo que ayuda a realizar el trabajo desde cualquier lugar, sin necesidad de tener un ordenador cerca.
ocrterminal.com es una aplicación de reconocimiento de texto que nos permite leer el contenido de archivos pdf, jpeg y otros formatos de imagen.
Lógicamente la calidad del resultado depende de la distribución y tipo de letra utilizado en el documento original, no es lo mismo recuperar el texto de un pdf con texto en Arial que de una imagen con texto escrito a mano.
Sea como sea OCRTerminal nos ofrece la posibilidad de obtener el texto pagando por página, teniendo cualquier usuario 20 páginas gratuitas por mes.
Aunque no sea 100% gratuita reconozco que puede ser muy útil, 10 páginas por menos de un dólar es, sinceramente, una ganga que puede ahorrarnos mucho tiempo.
Un programa OCR (Optical Character Recognition) es capaz de reconocer las palabras escritas en una imagen. Muy útil para crear documentos digitales a partir de textos escritos en papel.
Por supuesto la mayor dificultad de este tipo de programas es reconocer la letra escrita a mano, aunque en los últimos años se han hecho grandes avances al respecto.
Free-OCR.com es una web que nos permite obtener el texto de cualquier imagen en formato JPG, GIF, TIFF, BMP o PNG o documento PDF, reconociendo varios idiomas, español incluido.
Las imágenes no pueden ser mayores de 2 megas y tampoco podréis procesar más de 10 páginas por hora. No es necesario el registro, tan solo piden una dirección de email.
Lo he probado con algunas imágenes y, aunque el resultado no sea perfecto, sí nos puede ahorrar unas horas de trabajo.
Original forma la de pixolu de encontrar las imágenes que buscáis en Internet.
Inicialmente indicaréis una palabra, como en Google Image, por ejemplo, esperando a que pixolu devuelva una matriz de resultados obtenidos entre la base de datos de Google, Yahoo y flickr.
Una vez obtenidas las miniaturas tendréis que seleccionar las que más se parezcan con el resultado que deseáis, esperando otra colección de imágenes que pixolu obtendrá teniendo en cuenta los colores y formas de las miniaturas seleccionadas.
Una interesante forma de utilizar la tecnología de reconocimiento de imágenes para crear un buscador inteligente.
Hideki Kobayashi me manda una invitación para probar Gazopa y compartir la experiencia con vosotros.
Se trata de un buscador de imágenes relacionadas, algo que ya hemos visto algunas veces por aquí con unas características que lo hacen único, por ahora. Podéis buscar imágenes de tres formas: informando una palabra, a lo Google image, enviando una imagen y confiando en su sistema de reconocimiento de imágenes para obtener fotografías parecidas a la enviada o, lo más sorprendente, dibujando a mano lo que buscáis y esperando resultados que se parezcan a la figura trazada.
Abajo podéis ver el resultado después de haber dibujado torpemente la cara de un perro y ajustado os parámetros para obtener algo que se le parezca. Un excelente proyecto que nos demuestra lo inteligente que puede ser una aplicación cuando está programada con cariño.
Imaginemos que estáis paseando en la calle y veis un cartel anunciando una película de la que no habíais oído hablar. Sacáis vuestro móvil, hacéis una foto, la enviáis a m @ kooaba . ch y listo, Kooaba se encargará de recibir la foto, reconocer el texto incluido en ella y enviaros enlaces con más información sobre el tema enviado.
Una forma rápida de encontrar información sin tener que escribir una letra.
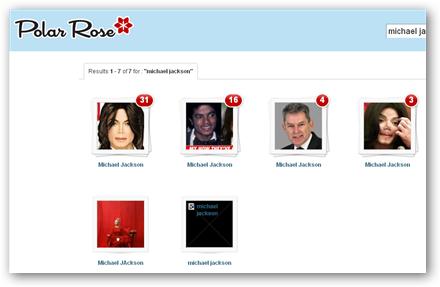
Polar Rose es una extensión que podréis instalar en vuestro navegador de Internet para poner nombres de las personas conocidas que véis en fotos de Internet.
Al estar aún en beta cerrada no tienen una base de reconocimiento muy grande. Ya he instalado la extensión y he podido comprobar que cada vez que aparece alguien en una foto de Internet me da la posibilidad de incluir el nombre de la persona. Si todos hicieran lo mismo en poco tiempo tendriamos un buscador de rostros prácticamente perfecto.
Sin duda utilizar la inteligencia de miles de usuarios genera una cantidad de datos mucho más fiable. Ninguna inteligencia artificial sería capaz de reconocer a Michael Jackson en todas sus fases:
Polar Rose usa un tecnología de código abierto que peude ser encontrada en Google Code y en el servidor Jetty Hightide.
Si estáis interesados en participar de la versión beta decídmelo que pediré las invitaciones correspondientes.


 Presentándose como un robot inteligente capaz de reconocer cualquier música que le enviemos, Audiotag.info muestra el título y autor de los archivos musicales que de los que no sabemos nada.
Presentándose como un robot inteligente capaz de reconocer cualquier música que le enviemos, Audiotag.info muestra el título y autor de los archivos musicales que de los que no sabemos nada.