KitchenAid, la marca que tiene una batidora planetaria en casi todas las cocinas que se precian, lanza su primer gadget conectado para cocinar: el KitchenAid Smart Thermometer. Lo publica Anna Washenko en Engadget el 13 de mayo de 2026. El dispositivo ya está a la venta en configuración de sonda única ($99,99) y doble ($199,99),… Continúa leyendo »


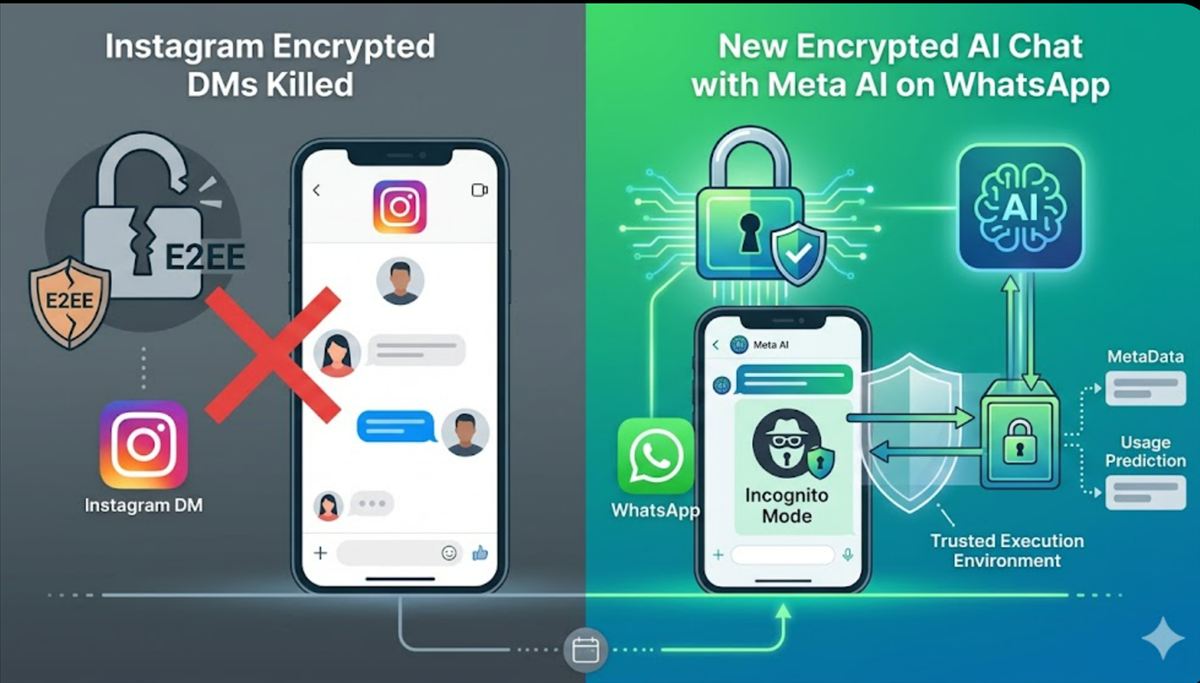
Meta y Google pagaron a Sesame Street, Girl Scouts y Highlights para enseñar moderación digital mientras diseñaban apps adictivas

Es la contradicción más documentada del sector tecnológico de los últimos dos años. Lo publica Reuters el 14 de mayo de 2026 en una investigación que cubre The Next Web: Meta y Google financiaron con decenas de millones de dólares a organizaciones infantiles de confianza —entre ellas Sesame Workshop, Girl Scouts y Highlights Magazine— para que enseñaran a los niños a usar la tecnología con moderación, mientras simultáneamente las propias compañías diseñaban las apps que hacían más difícil para esos niños desengancharse. Continúa leyendo «Meta y Google pagaron a Sesame Street, Girl Scouts y Highlights para enseñar moderación digital mientras diseñaban apps adictivas»