
Anthropic acaba de anunciar Claude Sonnet 4.6, una nueva versión de su familia Sonnet que apunta a un objetivo muy concreto: ofrecer un rendimiento cercano a su gama alta, Opus, con un coste y una disponibilidad más “prácticos” para el día a día. La propia compañía lo define como una actualización completa de habilidades en programación, uso del ordenador, razonamiento con contexto largo, planificación de agentes, trabajo de oficina y diseño, y lo coloca como modelo predeterminado para usuarios de planes Free y Pro en sus interfaces, según su comunicado y entrada oficial de producto (fuente: Anthropic).
En términos de acceso, Claude Sonnet 4.6 ya está disponible en los planes de Claude, en Claude Cowork, Claude Code, la API de Claude y también en “grandes plataformas cloud”, de acuerdo con la nota enviada a medios y el post del blog de la compañía. El detalle importante para quien mira presupuestos: el precio por API se mantiene respecto a Sonnet 4.5, con la referencia de 3/15 dólares por millón de tokens (entrada/salida) que Anthropic menciona en su anuncio.
Sonnet y Opus: la “berlina” que quiere conducir como un deportivo
Para entender el movimiento, conviene recordar la lógica de catálogo: Opus suele ser el modelo “tope de gama” y Sonnet la opción con mejor equilibrio. Si Opus es ese coche deportivo que sacas cuando necesitas el máximo agarre en la curva, Sonnet quiere ser la berlina cómoda que, sin buscar récords, acelera lo suficiente como para que casi nadie eche de menos el deportivo en trayectos normales.
Esa comparación no es casual. En su comunicación, Anthropic insiste en que Sonnet 4.6 “se acerca” a la inteligencia de Opus, con un punto de precio que lo hace más viable para muchas más tareas. David Gewirtz, en ZDNET, lo interpreta como el “daily driver” que busca cerrar la brecha con Opus sin penalizar a los usuarios de planes baratos o gratuitos (fuente: ZDNET).
Mejoras en coding: más consistencia y menos “sobreingeniería”
Uno de los titulares más repetidos del anuncio es la mejora en programación. Anthropic afirma que Sonnet 4.6 gana en consistencia, seguimiento de instrucciones y fiabilidad, y que en pruebas internas los desarrolladores lo prefirieron frente a Sonnet 4.5 alrededor del 70% de las veces. También sostienen que llegó a ser preferido frente a Claude Opus 4.5 en un porcentaje relevante de comparativas (fuente: Anthropic).
Traducido a sensaciones reales, el problema que muchos equipos han visto en modelos anteriores no es solo “si sabe programar”, sino si programa de forma útil: leer contexto antes de tocar código, evitar duplicar lógica, no inventarse que algo funciona cuando no se ha verificado. Anthropic dice que en Claude Code los probadores detectaron menos tendencia a la “pereza” y a la “sobreingeniería”, con menos afirmaciones falsas de éxito, menos alucinaciones y mejor seguimiento en tareas con varios pasos. Es como pasar de un becario brillante pero impulsivo a uno igual de rápido, pero que revisa el documento antes de enviar el correo.
Uso del ordenador: cuando la IA ya no necesita “conectores” para todo
Otra pata clave es el computer use, la capacidad de usar software “como lo haría una persona”, haciendo clic, escribiendo y navegando por interfaces. Anthropic ya había presentado este enfoque en 2024 como algo experimental; ahora asegura que Sonnet 4.6 mejora “de forma importante” frente a Sonnet anteriores. El benchmark que usan para ilustrarlo es OSWorld, una referencia habitual para medir tareas en aplicaciones reales dentro de un entorno simulado, sin APIs especiales ni integraciones hechas a mano. La compañía detalla que sus modelos Sonnet han ido mejorando en OSWorld durante 16 meses y que desde Sonnet 4.5 se usa OSWorld-Verified, una versión actualizada del benchmark (fuente: Anthropic).
Lo interesante aquí no es el gráfico, sino lo que implica para trabajo cotidiano. Anthropic menciona ejemplos concretos: moverse por una hoja de cálculo compleja, completar un formulario web de varios pasos y coordinar información entre varias pestañas del navegador. Si alguna vez has visto a alguien “perderse” entre pantallas, entenderás por qué esto importa: una IA que usa el ordenador reduce la necesidad de que cada herramienta tenga integración perfecta. Es como tener un compañero que aprende a usar el programa heredado del departamento de contabilidad sin pedirle al equipo de IT que programe un conector nuevo.
Ventana de 1 millón de tokens: contexto largo que no se deshilacha
Una de las novedades más llamativas es la ventana de contexto de 1M tokens en beta. Poner un número tan grande suena abstracto, así que vale una metáfora: si un modelo clásico trabaja con una mesa de comedor, una ventana de 1 millón de tokens es una mesa de banquete. Caben un código base entero, contratos largos o decenas de papers en una sola sesión, según la propia Anthropic.
El matiz importante es el segundo: no basta con “meterlo todo”, hace falta razonar bien sin perder el hilo. Anthropic recalca que Sonnet 4.6 mantiene un razonamiento efectivo a través de ese contexto largo, lo que impacta especialmente en planificación a largo plazo y tareas que crecen por capas, como proyectos de software con decisiones acumulativas (fuente: Anthropic). En la práctica, para quien trabaja con documentación y cambios iterativos, esto reduce ese efecto de “teléfono roto” en el que la IA olvida por qué se tomó una decisión veinte mensajes atrás.
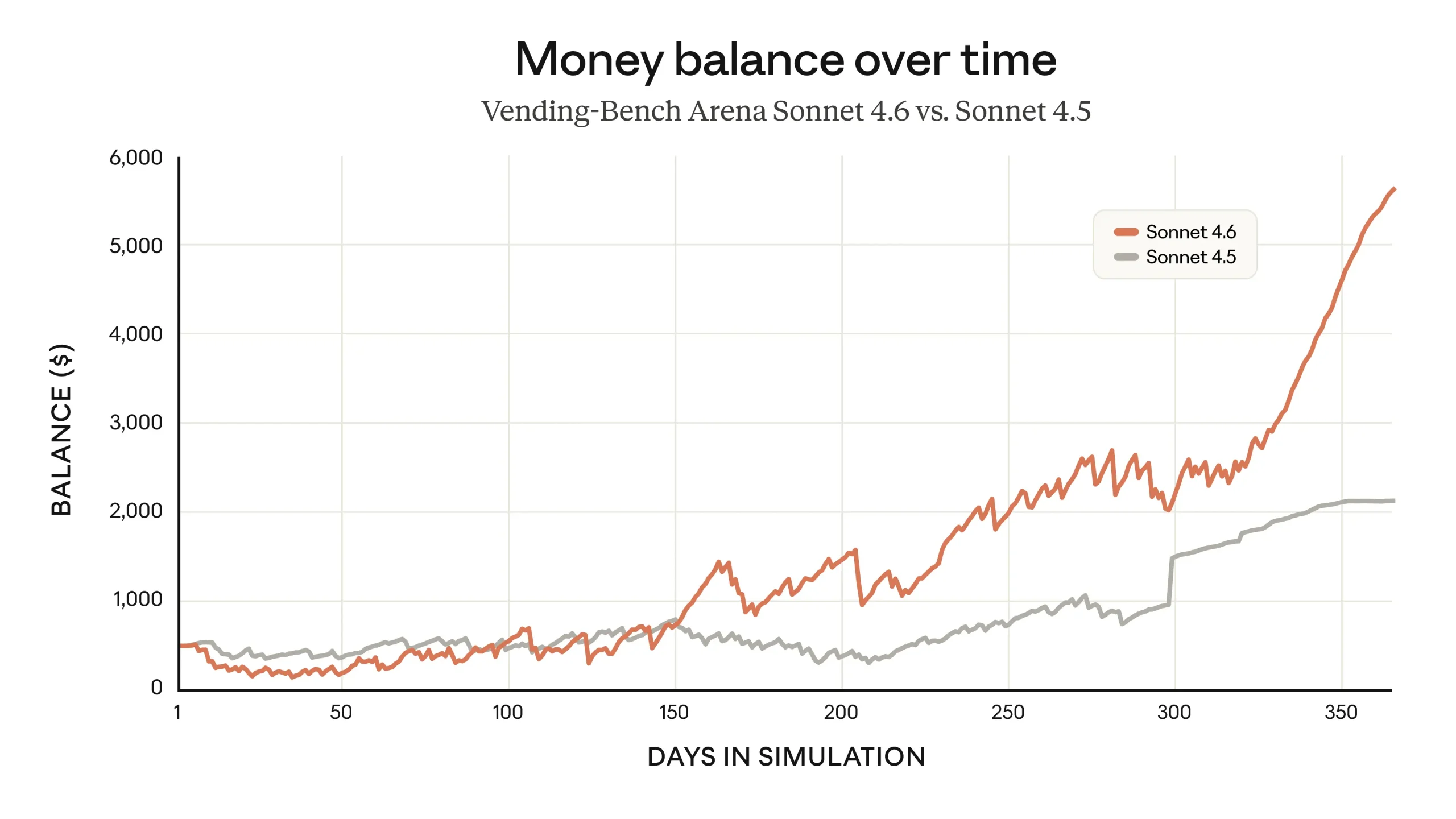
Planificación y evaluación: el caso de Vending-Bench Arena
Para sostener la idea de planificación a largo plazo, Anthropic cita una evaluación llamada Vending-Bench Arena, pensada para medir cómo un modelo “gestiona un negocio” simulado a lo largo del tiempo. Según la compañía, Sonnet 4.6 adoptó una estrategia curiosa: invertir fuerte en capacidad durante los primeros diez meses simulados y pivotar con decisión hacia la rentabilidad al final, logrando un resultado superior en esa evaluación (fuente: Anthropic).
Más allá del benchmark, el ejemplo sirve para entender la mejora en “horizonte”: no es solo responder bien a una pregunta, sino sostener una estrategia coherente durante una partida larga, como quien primero compra estanterías y stock para una tienda y solo luego optimiza márgenes cuando ya puede vender con fluidez.
Herramientas para desarrolladores: API, ejecución de código y “compaction”
En la parte de plataforma, Anthropic también anuncia cambios relevantes. En su Developer Platform, Sonnet 4.6 soporta modos de pensamiento adaptativo y extendido, y ofrece context compaction en beta, un mecanismo que resume contexto antiguo cuando la conversación se acerca al límite, para estirar la utilidad del historial sin perder lo importante (fuente: Anthropic).
En la API de Claude, la compañía señala que las herramientas de búsqueda y “fetch” web ahora pueden escribir y ejecutar código automáticamente para filtrar y procesar resultados, reteniendo solo lo relevante en el contexto. También mencionan como disponibilidad general la ejecución de código, web fetch, memoria, llamadas programáticas de herramientas, búsqueda de herramientas y ejemplos de uso (fuente: Anthropic). Para un equipo que arma agentes, esto se parece a pasar de una navaja suiza con pocas piezas a una caja de herramientas completa: menos pegamento manual, más flujos reproducibles.
Claude en Excel y conectores MCP: datos financieros sin salir de la hoja
Una novedad con sabor claramente corporativo es el soporte de MCP connectors para Claude en Excel en planes Pro, Max, Team y Enterprise. Anthropic dice que esto permite usar conectores hacia fuentes como S&P Global, LSEG, Daloopa, PitchBook, Moody’s y FactSet, trayendo contexto externo directamente a la hoja de cálculo sin saltar entre pestañas o aplicaciones. Si ya se usan conectores MCP en Claude.ai, esas conexiones se heredan en Excel (fuente: Anthropic).
Para quien vive entre celdas, esto puede ser más relevante que cualquier benchmark: pedirle a la IA que combine datos externos con tu modelo financiero y los deje listos en la misma plantilla es una mejora de flujo de trabajo muy tangible.
Seguridad: prompt injection y evaluaciones internas
El aumento de “uso del ordenador” trae riesgos propios. Anthropic menciona explícitamente los ataques de prompt injection, donde se ocultan instrucciones maliciosas en páginas web o contenidos para desviar el comportamiento del modelo. Según sus evaluaciones, Sonnet 4.6 mejora de forma importante frente a Sonnet 4.5 en resistencia a este tipo de ataques, y se comporta de forma similar a Opus 4.6 en ese aspecto (fuente: Anthropic).
La compañía también afirma haber realizado evaluaciones extensas de seguridad y concluye que Sonnet 4.6 es tan seguro como otros modelos recientes, con comportamientos de seguridad fuertes y sin señales de grandes preocupaciones en desalineamientos de alto riesgo, según su investigación interna y documentación asociada (fuente: Anthropic).
Cuándo tiene sentido usar Sonnet 4.6 y cuándo subir a Opus 4.6
En el propio mensaje de Anthropic hay una recomendación implícita: Sonnet 4.6 rinde bien incluso con “extended thinking” desactivado y permite explorar el equilibrio entre velocidad y fiabilidad según lo que estés construyendo. Para tareas de código y productividad general, Sonnet busca ser la opción por defecto.
Aun así, Anthropic conserva el papel de Opus 4.6 como el escalón para lo que exige la máxima profundidad de razonamiento, como refactors grandes de bases de código, coordinación de múltiples agentes o trabajos donde “tiene que quedar perfecto” (fuente: Anthropic). En lenguaje cotidiano: Sonnet 4.6 te resuelve la mayoría de recados con solvencia; Opus 4.6 sigue siendo el especialista al que llamas cuando el margen de error es mínimo.