
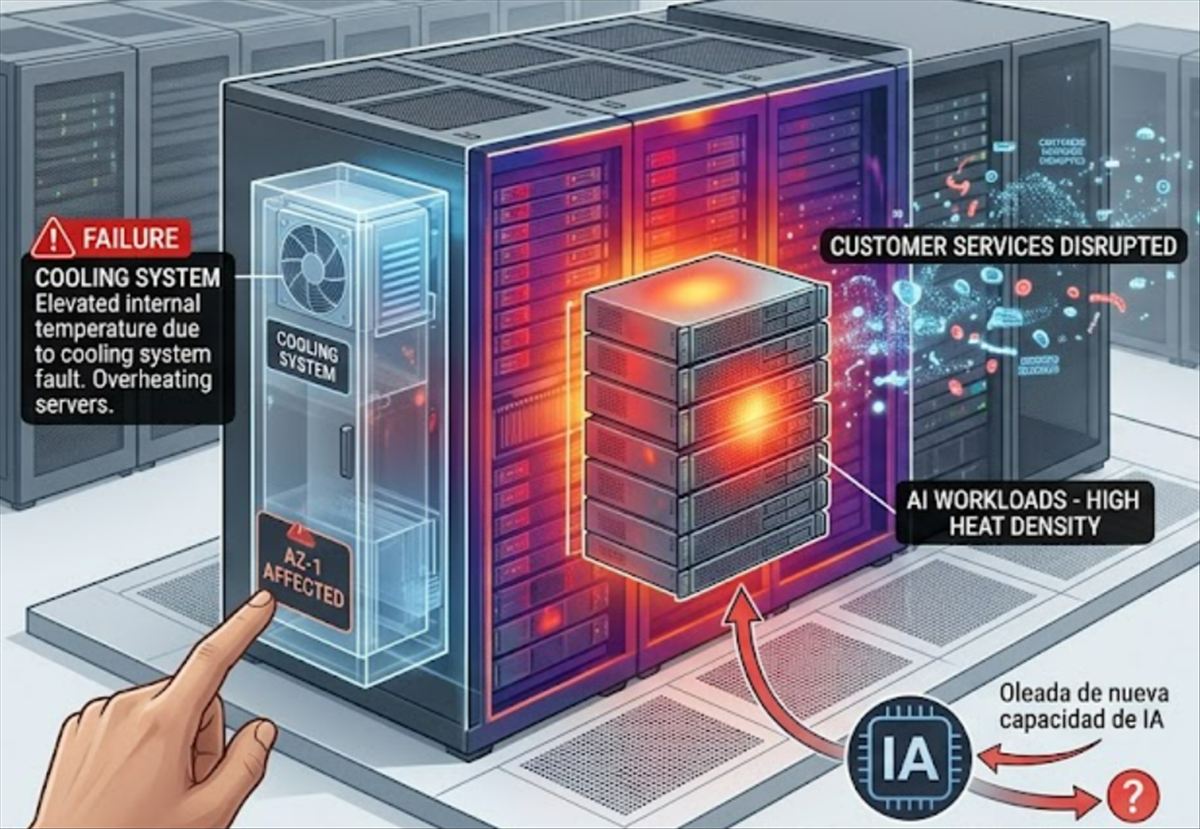
El 8 de mayo, Amazon Web Services reportó que uno de sus centros de datos en el norte de Virginia —la región US-East-1, la más antigua y concentrada de AWS— sufrió temperaturas internas elevadas causadas por un fallo en el sistema de refrigeración. El resultado: servicios de clientes interrumpidos, Coinbase fuera de línea durante varias horas, y el mercado de derivados CME Group con problemas en su plataforma CME Direct. Lo publica Ana-Maria Stanciuc en TheNextWeb.
El fallo fue técnicamente contenido: AWS localizó el problema en una única Availability Zone (una agrupación de uno o más centros de datos diseñados para operar de forma independiente) y redirigió el tráfico a las otras zonas de la región. La capacidad de refrigeración adicional comenzó a activarse un par de horas después de los primeros reportes de impacto. Pero una actualización posterior fue menos tranquilizadora: instalar suficiente refrigeración adicional para reiniciar de forma segura todos los sistemas afectados estaba tomando más tiempo del esperado.
Coinbase confirmó que sus problemas eran causados directamente por el evento de AWS. Tras varias horas de mercados degradados, la exchange confirmó que todos los mercados estaban de nuevo operativos. CME Group reportó «mantenimiento esencial» en su plataforma durante la misma ventana temporal, aunque no confirmó explícitamente si el evento de AWS fue la causa.
US-East-1: la región que acumula todo
El problema de fondo no es el fallo de refrigeración en sí —los equipos fallan—, sino la concentración de carga en US-East-1. Esta región, lanzada por AWS en 2006, es la más antigua y más cargada del catálogo de AWS. Ha acumulado durante 20 años la inercia de clientes que construyeron sus arquitecturas cuando US-East-1 era la única opción y nunca migraron a una configuración multi-región. En términos de arquitectura cloud, eso es como construir una ciudad entera alrededor de una sola central eléctrica porque era la primera que se instaló.
La recomendación oficial de AWS durante el incidente era la estándar en sus guías de buenas prácticas desde hace años: «los clientes que operen en la Availability Zone afectada deben hacer failover a otra.» Esa recomendación funciona perfectamente para los equipos que han construido para ello. Funciona mucho peor para los que no.
El incidente tiene un contexto adicional que TheNextWeb señala con precisión: US-East-1 ha absorbido en el último año una oleada de nueva capacidad de entrenamiento e inferencia de IA, que genera más calor y funciona a mayor densidad que las cargas de trabajo cloud tradicionales. El informe de postmortem de AWS tendrá que responder si la expansión acelerada de workloads de IA en la región fue un factor en el fallo de refrigeración, o simplemente una coincidencia cronológica.
El patrón es recurrente: en octubre pasado, un fallo de resolución DNS en DynamoDB causó una caída de más de 14 horas que afectó a Snapchat, Reddit, United Airlines y a la propia Coinbase. Un mes después, CME sufrió una de sus paradas de trading más largas en años, trazada hasta un fallo de refrigeración en un centro de datos de CyrusOne en Chicago.
Por qué CME es un caso especialmente delicado
Los mercados de derivados financieros de CME no degradan de forma elegante. Sus pipelines de márgenes y liquidación tienen deadlines que mueven dinero la mañana siguiente al cierre de la sesión asiática. Una parada durante la sesión de Asia —como la del jueves, que llegó en horario de pico asiático— impacta ciclos de liquidación que ya están en curso.
Si el análisis posterior confirma que la plataforma de CME estaba afectada por el evento de AWS, la conversación regulatoria sobre resiliencia de infraestructura de mercados financieros en la nube se intensificará. Los reguladores llevan años monitorizando la concentración de dependencia de hyperscalers en infraestructura financiera crítica.
Mi valoración
Llevo cubriendo interrupciones de infraestructura cloud desde los primeros grandes apagones de AWS en 2011, y el incidente de hoy en US-East-1 es nuevo en el mecanismo (refrigeración) pero idéntico en la lección: el punto de fallo sigue siendo la concentración geográfica y lógica en una sola región, que ningún avance en IA ni en cloud computing modifica.
Lo que más me preocupa del incidente de hoy no es el fallo en sí —que es resoluble con redundancia de refrigeración— sino el timing con la expansión de IA. Si los workloads de entrenamiento e inferencia están llenando US-East-1 a densidades y temperaturas que la infraestructura de refrigeración existente no anticipó, el problema no es puntual. Es estructural, y se repetirá mientras la demanda de IA siga creciendo más rápido que la capacidad de refrigeración.
Preguntas frecuentes
¿Qué es una Availability Zone de AWS y por qué falla solo una y no toda la región?
Una Availability Zone (AZ) es una agrupación de uno o más centros de datos físicos dentro de una región de AWS, con alimentación eléctrica, refrigeración y red independientes de las otras AZs de la misma región. AWS diseña sus regiones con múltiples AZs para que el fallo de una no afecte a las otras. El problema es cuando los clientes corren toda su arquitectura en una sola AZ en lugar de distribuirla entre varias.
¿Por qué US-East-1 concentra tanto tráfico si AWS tiene decenas de regiones?
US-East-1 fue la primera región de AWS, lanzada en 2006. Durante años fue la única opción real, y los clientes construyeron sus arquitecturas allí. Migrar arquitecturas complejas a otras regiones es costoso y arriesgado, así que la mayoría ha optado por quedarse. Esa inercia de 20 años hace que US-East-1 siga siendo la región más cargada del catálogo de AWS, aunque no sea la más moderna.
¿Qué debería hacer una empresa para evitar este tipo de interrupción?
El consejo estándar de AWS —y de cualquier arquitecto de cloud— es diseñar para multi-AZ como mínimo y multi-región para servicios críticos. Eso significa tener réplicas activas en más de una Availability Zone y, para los servicios donde la interrupción tiene coste real (trading, pagos, comunicaciones críticas), réplicas en más de una región geográfica. El coste de esa redundancia suele ser significativamente menor que el coste de una interrupción.