

Hay muchas formas de transcribir archivos de audio en Internet. Hasta hace poco yo usaba HappyScribe, pero desde hace unas semanas me he cambiado para poder reducir los costes en audios largos.
Es por eso que os voy a hablar de OpenAI Whisper, un avance significativo en el campo del reconocimiento automático de voz (ASR). Este modelo fue desarrollado por OpenAI, una organización líder en el campo de la inteligencia artificial, conocida por sus contribuciones innovadoras como GPT-3 y DALL-E.
El modelo Whisper fue presentado oficialmente por OpenAI en septiembre de 2022. Su desarrollo se basó en una extensa y variada base de datos de audio, comprendiendo aproximadamente 680,000 horas de contenido multilingüe y multitarea supervisado, recolectado de la web. Esta diversidad de datos fue clave para lograr una robustez y precisión cercana al nivel humano en el reconocimiento de voz en inglés.
A diferencia de otros modelos de ASR, Whisper se destaca por su capacidad para realizar reconocimiento de voz multilingüe, traducción de voz y identificación de idiomas. Su arquitectura es una implementación simple de extremo a extremo, utilizando un Transformer como encoder-decoder. Este enfoque permite al modelo procesar eficientemente el audio en trozos de 30 segundos, convertirlos en un espectrograma log-Mel y luego predecir el texto correspondiente.
Principios básicos del reconocimiento automático de voz
El reconocimiento automático de voz es una tecnología que permite a las computadoras entender y procesar el habla humana, convirtiéndola en texto o comandos ejecutables. Esta tecnología se basa en algoritmos de aprendizaje automático y procesamiento del lenguaje natural, que analizan las características acústicas y lingüísticas del habla.
La importancia del ASR radica en su amplia gama de aplicaciones, desde la accesibilidad para personas con discapacidades auditivas hasta su uso en asistentes virtuales, dispositivos inteligentes, servicios de transcripción y más. En el contexto actual, donde la interacción fluida entre humanos y máquinas es cada vez más crucial, el ASR juega un papel fundamental en la creación de interfaces más naturales y accesibles.
La llegada de modelos como OpenAI Whisper representa un hito en este campo, no solo por su capacidad para manejar una amplia variedad de idiomas y acentos, sino también por su habilidad para adaptarse a distintos contextos y entornos ruidosos, superando así muchas de las limitaciones que presentaban los modelos anteriores.
Características clave de OpenAI Whisper
Como ya os he comentado, una de las características más destacadas de OpenAI Whisper es su capacidad multilingüe. El modelo ha sido entrenado en una amplia gama de idiomas, lo que le permite realizar reconocimiento de voz en varios idiomas con una precisión notable. Esta capacidad multilingüe es especialmente valiosa en un mundo globalizado, donde la capacidad de procesar y entender múltiples idiomas es crucial.
El soporte de idiomas de Whisper no se limita solo al reconocimiento de voz, sino que también incluye la capacidad de traducir el habla a texto en diferentes idiomas. Esta funcionalidad es esencial para aplicaciones como servicios de traducción en tiempo real y asistencia en la comunicación entre hablantes de diferentes idiomas. La habilidad de Whisper para manejar diferentes acentos y dialectos dentro de un mismo idioma también es un factor importante, ya que aumenta su utilidad en entornos multiculturales y diversificados.
Integración con otras tecnologías y servicios
Whisper ha sido integrado en varios servicios y tecnologías para mejorar su accesibilidad y aplicabilidad. Un ejemplo notable es su integración con Azure OpenAI Service y Azure AI Speech, lo que permite a los usuarios aprovechar las capacidades de reconocimiento de voz de Whisper dentro del ecosistema de Microsoft Azure. Esta integración facilita a las empresas y desarrolladores la incorporación de Whisper en sus aplicaciones y servicios, aprovechando la infraestructura y las capacidades de Azure para una implementación más eficiente y segura.
La combinación de Whisper con otras tecnologías y plataformas amplía significativamente sus posibles aplicaciones. Desde mejorar la accesibilidad en aplicaciones web hasta su uso en análisis de datos de voz en la nube, la integración de Whisper con servicios existentes abre un mundo de posibilidades para desarrolladores y empresas.
Actualizaciones y versiones Recientes de OpenAI Whisper
La versión más reciente y destacada de OpenAI Whisper es la «Whisper large-v3». Esta versión representa una evolución significativa respecto a sus predecesores, ofreciendo mejoras notables en precisión y versatilidad. Una de las actualizaciones clave en la versión large-v3 es la mejora en la robustez del modelo, lo que le permite manejar una gama más amplia de acentos y variaciones en el habla con mayor precisión. Esto es especialmente importante en el reconocimiento de voz en idiomas con una amplia diversidad de acentos y dialectos.
La versión large-v3 ha experimentado mejoras en la eficiencia del procesamiento. Esto incluye la optimización del uso de la memoria y la velocidad de procesamiento, lo que resulta en un rendimiento más rápido y eficaz, especialmente en dispositivos con recursos limitados. Estas mejoras son cruciales para aplicaciones que requieren respuesta en tiempo real o que operan en entornos con restricciones de hardware.
El modelo Whisper se basa en una arquitectura de Transformer de encoder-decoder, que ha sido un avance significativo en el procesamiento del lenguaje natural. Esta arquitectura permite que el modelo maneje eficientemente tareas complejas de procesamiento de voz, como la transcripción multilingüe y la traducción de voz a texto.
Una de las innovaciones clave en esta arquitectura es la capacidad del modelo para procesar audio en trozos de 30 segundos y convertirlos en espectrogramas log-Mel. Esto facilita la comprensión y transcripción del contenido del habla con una precisión notable. Además, el modelo utiliza tokens especiales que le permiten realizar múltiples tareas, como la identificación de idiomas, la transcripción de voz y la traducción a otros idiomas.
Otra innovación importante es la introducción de técnicas como «Flash Attention» y «Torch Scale-Product-Attention (SDPA)» en la versión large-v3. Estas técnicas mejoran la eficiencia del modelo al procesar grandes volúmenes de datos, reduciendo significativamente el tiempo y los recursos necesarios para la transcripción y la traducción de voz.
Cómo se usa
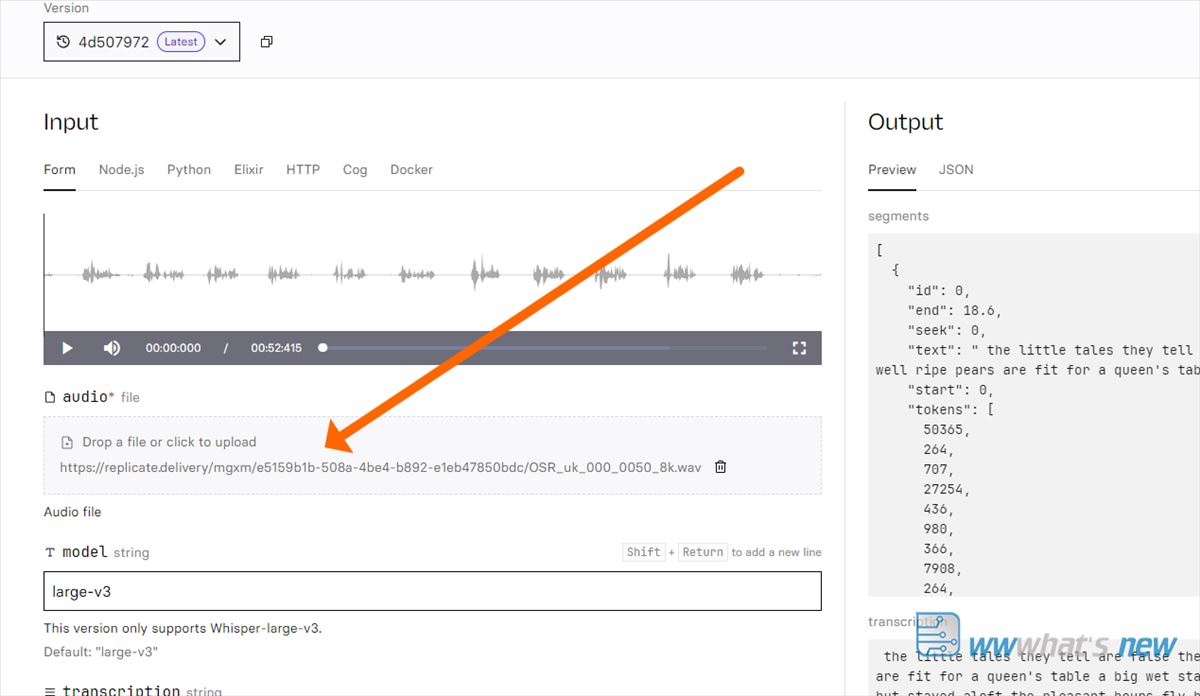
Solo tenéis que acceder a replicate.com/openai/whisper y subir el archivo donde apunto con la flecha. Una vez subido, si no ponéis el idioma, lo detectará automáticamente y comenzará el trabajo, que tendréis en texto al finalizar en la parte derecha.
De esta forma se puede usar incluso sin registro en la página, sin crear cuenta, y cuando se acabe el crédito gratis, se puede abrir una ventana en incógnito y probarlo de nuevo.
Si queréis poder abrir cuenta y pagar por consumo de tiempo.
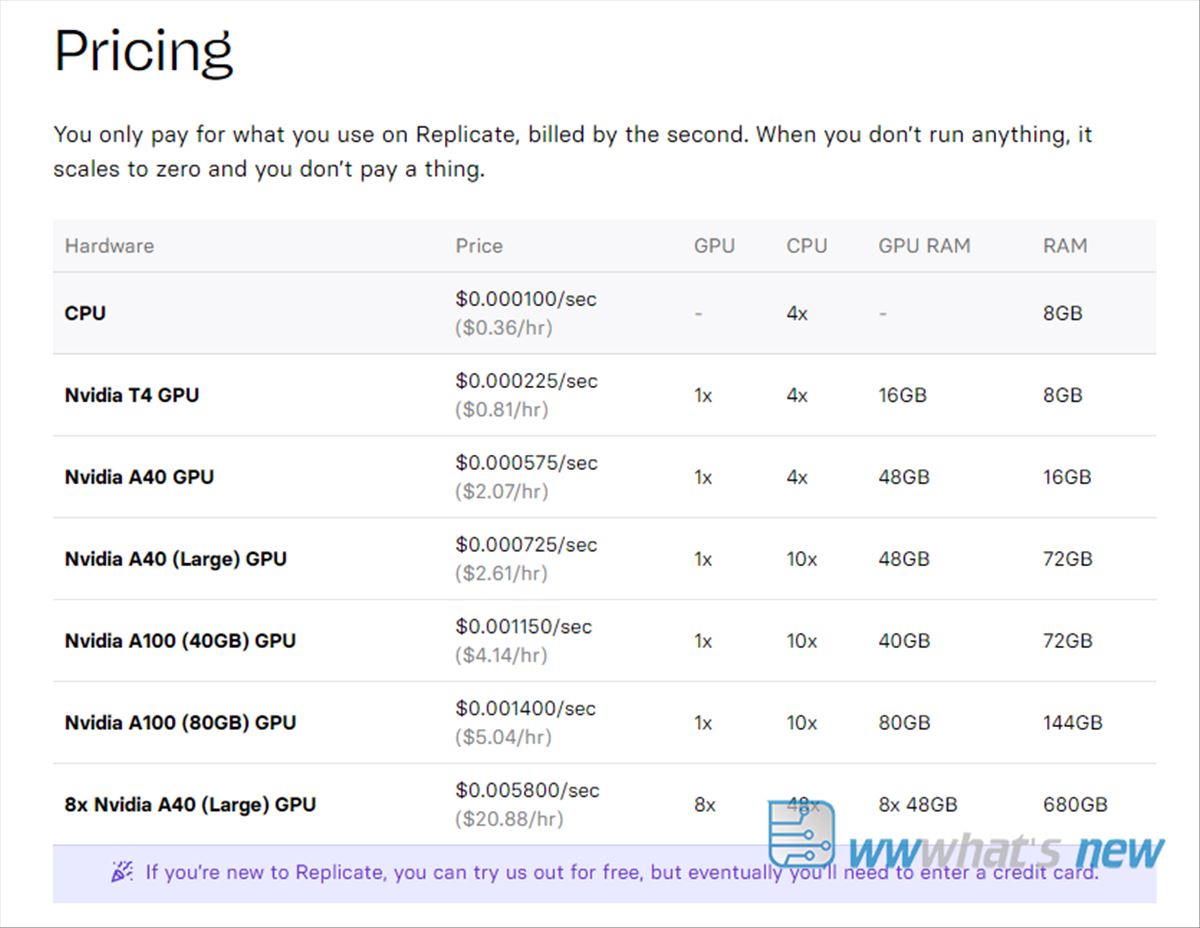
También podéis instalar el modelo y usar una API. Estos son los pasos generales para la instalación y configuración del modelo:
- Requisitos Previos: Es esencial tener Python instalado en su sistema, ya que Whisper está basado en Python. La versión recomendada es Python 3.9 o superior.
- Instalación del Modelo: Puede instalar Whisper directamente desde GitHub o mediante herramientas de gestión de paquetes como pip. El comando típico de instalación sería algo así como
pip install git+https://github.com/openai/whisper.git. Esto instalará Whisper junto con las dependencias necesarias. - Descarga de Modelos Preentrenados: Whisper ofrece varios modelos preentrenados de diferentes tamaños. Puede elegir y descargar el modelo que mejor se adapte a sus necesidades, como
large-v3para obtener un rendimiento óptimo. - Configuración del Entorno de Ejecución: Asegúrese de que su entorno de ejecución esté correctamente configurado, especialmente si va a utilizar Whisper para procesamiento intensivo de datos o en un entorno de producción.
- Pruebas Iniciales: Realice pruebas iniciales para asegurarse de que el modelo esté funcionando correctamente. Puede hacer esto ejecutando un comando de transcripción simple en una muestra de audio.
Como veis, aunque la interfaz no es extremadamente amigable, el modelo es de lo mejor que existe, por lo que aprovechad, y a transcribir como si no hubiera un mañana.