
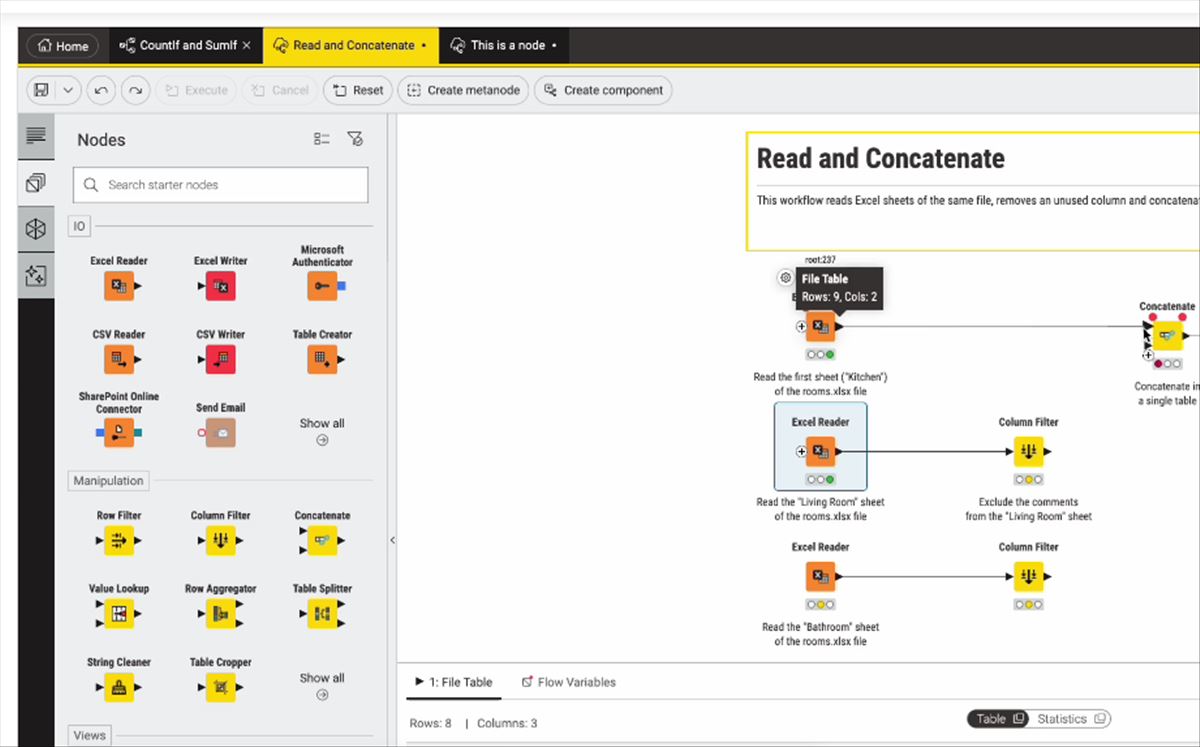
KNIME es una plataforma de código abierto para el análisis y modelado de datos que ofrece una amplia variedad de posibilidades para crear flujos de trabajo de datos (también conocidos como workflows).
La idea es que podamos establecer un archivo inicial con datos, una serie de nodos para trabajar con ellos y un resultado que pueda ser exportado.
Aquí tienes diez ejemplos interesantes de flujos de datos que pueden ser implementados en KNIME, cada uno enfocado en diferentes usos y aplicaciones:
- Limpieza de Datos: Un flujo básico pero esencial que incluye pasos para la eliminación de valores faltantes, corrección de errores tipográficos, normalización de datos y filtrado de filas o columnas innecesarias. Este flujo es fundamental antes de realizar cualquier análisis más profundo.
- Análisis Exploratorio de Datos (EDA): Este flujo utiliza nodos para estadísticas descriptivas, histogramas, boxplots y scatter plots para explorar y entender las distribuciones y relaciones en los datos.
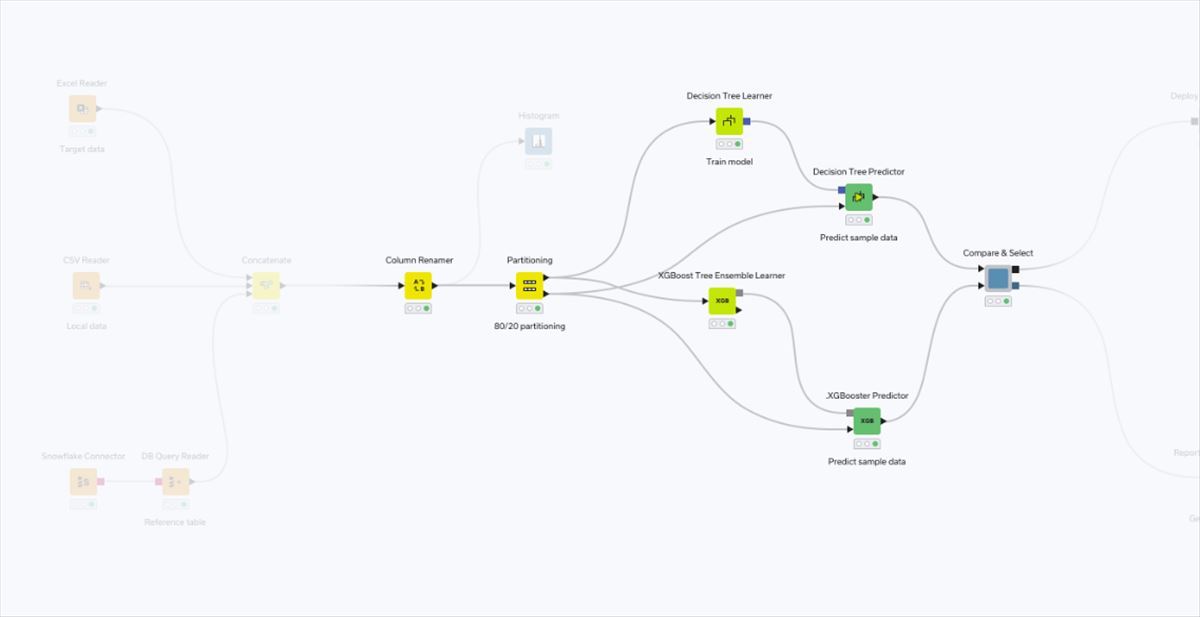
- Modelado Predictivo: Crear un flujo de trabajo que incluya la división de datos en conjuntos de entrenamiento y prueba, entrenamiento de varios modelos de machine learning (como árboles de decisión, bosques aleatorios, o máquinas de soporte vectorial), y la evaluación de estos modelos usando métricas como la precisión, el F1-score, o el área bajo la curva ROC.
- Integración de Datos: Un flujo que ejemplifica la combinación de datos de múltiples fuentes, como bases de datos SQL, archivos Excel, y APIs web, para crear un conjunto de datos consolidado que pueda ser utilizado para análisis o reporting.
- Automatización de Reportes: Utilizar KNIME para automatizar la generación de reportes, extrayendo datos, realizando análisis y visualizaciones, y exportando el resultado a formatos como PDF o Excel.
- Procesamiento de Texto: Un flujo de datos para el análisis de texto que incluye tokenización, eliminación de palabras comunes (stopwords), análisis de sentimiento, y visualización de frecuencias de palabras.
- Recomendación de Productos: Crear un sistema de recomendación que use técnicas como filtrado colaborativo o factorización de matrices para sugerir productos a usuarios basándose en sus preferencias y comportamientos anteriores.
- Detección de Anomalías: Configurar un flujo para identificar datos atípicos o patrones anormales en tiempo real, útil para la detección de fraude o fallos en sistemas de monitoreo.
- Optimización de Parámetros de Modelos de Machine Learning: Usar la optimización de parámetros en KNIME para ajustar automáticamente los parámetros de los modelos de machine learning con el objetivo de mejorar el rendimiento del modelo.
- Integración con Python y R: Desarrollar flujos que integren scripts de Python o R para realizar análisis especializados o utilizar bibliotecas que no están disponibles directamente en KNIME.
Cada uno de estos flujos puede ser configurado y personalizado en KNIME para adaptarse a las necesidades específicas del proyecto, pero os voy a dar el paso a paso de los nodos que deberían usarse en cada punto.
Nodos usados en estos ejemplos
Limpieza de Datos:
- File Reader: Para cargar datos.
- Missing Value: Para manejar valores faltantes.
- Row Filter: Para eliminar filas bajo ciertas condiciones.
- Column Filter: Para seleccionar columnas específicas.
- Normalizer: Para normalizar los datos.
Análisis Exploratorio de Datos (EDA):
- Statistics: Para estadísticas descriptivas.
- Histogram: Para visualizar distribuciones.
- Box Plot: Para observar outliers.
- Scatter Plot: Para visualizar relaciones entre variables.
Modelado Predictivo:
- Partitioning: Para dividir datos en entrenamiento y prueba.
- Decision Tree Learner: Para entrenar un modelo de árbol de decisiones.
- Random Forest Learner: Para entrenar un modelo de bosque aleatorio.
- Scorer: Para evaluar el modelo.
Integración de Datos:
- File Reader / Database Reader / Table Reader: Para cargar datos de diversas fuentes.
- Concatenate: Para combinar tablas verticalmente.
- Joiner: Para unir tablas horizontalmente.
Automatización de Reportes:
- Data to Report: Para comenzar la configuración del reporte.
- BIRT Report Designer: Para diseñar y formatar reportes.
- Excel Writer: Para exportar resultados a Excel.
Procesamiento de Texto:
- Strings To Document: Para convertir texto en documentos.
- Punctuation Erasure: Para eliminar puntuación.
- Stop Word Filter: Para eliminar palabras comunes.
- Tag Cloud: Para visualizar palabras frecuentes.
Recomendación de Productos:
- Item-Based Collaborator Filter Node: Para recomendaciones basadas en item.
- User-Based Collaborator Filter Node: Para recomendaciones basadas en usuario.
- Association Rule Learner: Para encontrar reglas de asociación frecuentes.
Detección de Anomalías:
- Isolation Forest: Para identificar anomalías.
- Outlier Score: Para calcular puntuaciones de anomalías.
- Rule-based Row Filter: Para filtrar datos basados en reglas específicas.
Optimización de Parámetros de Modelos de Machine Learning:
- Parameter Optimization Loop Start: Para iniciar la optimización.
- Decision Tree Learner: Para ajustar el modelo dentro del bucle.
- Parameter Optimization Loop End: Para finalizar la optimización.
Integración con Python y R:
- Python Script: Para ejecutar código Python.
- R Snippet: Para ejecutar código R.
- R View: Para visualizaciones específicas en R
Como veis, el poder de KNIME es enorme, ahora os toca a vosotros bajar la herramienta y empezar a jugar con ella.
Enlace: knime.com