


La tecnología avanza a un ritmo vertiginoso y con ella, la adopción de la inteligencia artificial y el aprendizaje automático se ha vuelto una constante en una amplia gama de industrias. Desde sistemas de recomendación que nos sugieren nuestra próxima película o libro, hasta diagnósticos médicos avanzados y vehículos autónomos, el aprendizaje automático es el motor subyacente que impulsa estas maravillas tecnológicas. Pero para comprender realmente cómo se desarrollan estas soluciones, necesitamos explorar los fundamentos de dos métodos cruciales en el aprendizaje automático: el aprendizaje supervisado y el aprendizaje no supervisado.
Al sumergirnos en el mundo del aprendizaje automático, descubriremos que los algoritmos de aprendizaje pueden ser clasificados, en gran medida, en dos categorías: supervisados y no supervisados. Ambas categorías se diferencian principalmente en el tipo de datos que utilizan para el entrenamiento, y esta distinción juega un papel crucial en la forma en que los modelos aprenden, interpretan y generan predicciones o resultados a partir de los datos.
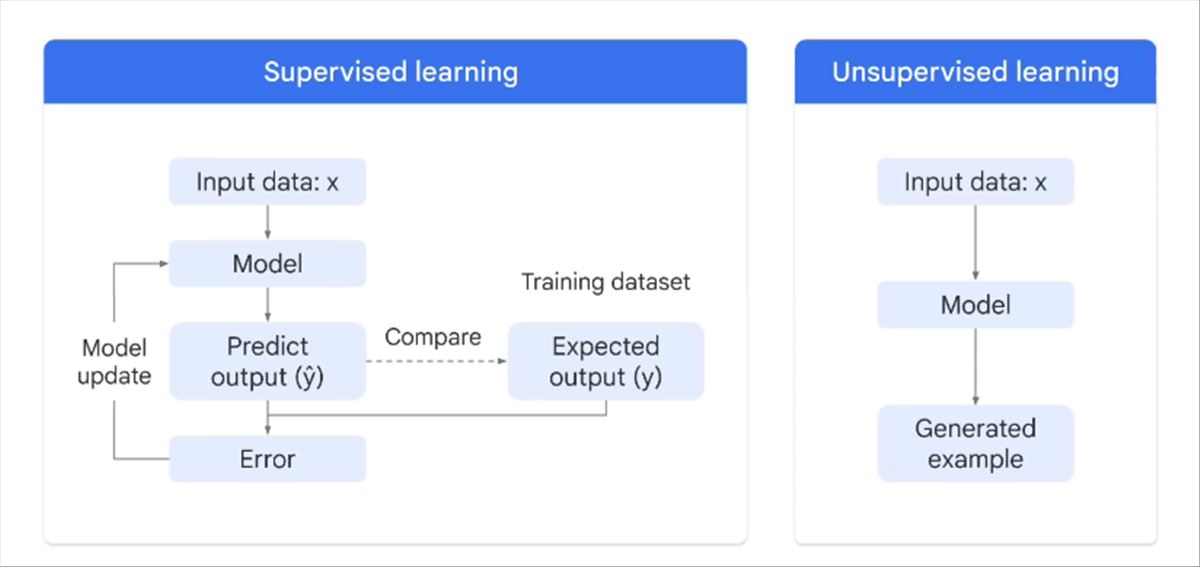
El aprendizaje supervisado se asemeja a un profesor guiando a un estudiante, donde el modelo se entrena con datos completos, es decir, datos que incluyen tanto las características de entrada como las etiquetas de salida correspondientes. Por otro lado, el aprendizaje no supervisado es más parecido a un alumno autodidacta, que debe encontrar patrones y estructuras en los datos sin ninguna guía explícita o etiquetas predefinidas.
Es decir:

Aprendizaje Supervisado
En el aprendizaje supervisado, tenemos un conjunto de datos de entrenamiento completo que incluye tanto las características de entrada como las etiquetas de salida correspondientes. Durante el entrenamiento, el modelo aprende a predecir la salida a partir de las características de entrada. Una vez que el modelo está entrenado, se puede utilizar para predecir la salida para nuevas instancias de entrada. Los modelos de aprendizaje supervisado se utilizan a menudo en tareas de clasificación y regresión. Ejemplos de modelos de aprendizaje supervisado incluyen regresión lineal, regresión logística, máquinas de vectores de soporte (SVM) y redes neuronales.
Veamos algunos ejemplos con más detalle:
Ejemplo de Aprendizaje supervisado en el correo electrónico
Un ejemplo común de aprendizaje supervisado es la detección de correos electrónicos spam. En este caso, el modelo de aprendizaje automático se entrena para clasificar si un correo electrónico es spam (correo no deseado) o no spam (correo legítimo).
Recopilación de datos y preprocesamiento
Primero, necesitaríamos recopilar un conjunto de datos que consiste en correos electrónicos que ya han sido clasificados como spam o no spam. Este conjunto de datos es necesario para entrenar nuestro modelo. Cada correo electrónico en este conjunto de datos se conoce como una «instancia» o un «ejemplo».
Las instancias en este caso pueden tener varias «características» o «atributos», como el asunto del correo electrónico, el cuerpo del correo electrónico, la dirección de correo electrónico del remitente, la hora del día en que se envió el correo electrónico, entre otros.
Sin embargo, los modelos de aprendizaje automático no pueden manejar texto directamente. Por lo tanto, necesitamos convertir estas características textuales en una forma numérica que el modelo pueda entender. Este proceso se conoce como «vectorización» y una técnica común para hacerlo es el método de «bolsa de palabras» (Bag of Words), que cuenta la frecuencia de las palabras en cada correo electrónico.
Entrenamiento del modelo
Una vez que tenemos nuestros datos preprocesados, podemos usarlos para entrenar nuestro modelo. Digamos que decidimos usar una regresión logística para este propósito. Durante el entrenamiento, el modelo aprenderá los pesos o coeficientes para cada palabra en función de su correlación con el correo electrónico que es spam o no.
Por ejemplo, el modelo puede aprender que los correos electrónicos que contienen la palabra «lotería» tienen más probabilidades de ser spam, por lo que asignará un peso más alto a esa palabra.
Evaluación y predicción
Después de que el modelo ha sido entrenado, podemos usarlo para predecir si un nuevo correo electrónico, que el modelo no ha visto antes, es spam o no. Este correo electrónico se convierte en un vector de palabras (como se hizo en la etapa de preprocesamiento), y este vector se alimenta al modelo.
El modelo luego utiliza los pesos que aprendió durante el entrenamiento para calcular una puntuación para este correo electrónico. Si la puntuación supera un cierto umbral, el correo electrónico se clasifica como spam; de lo contrario, se clasifica como no spam.
Este es un ejemplo típico de cómo se puede utilizar el aprendizaje supervisado para resolver un problema de clasificación en la vida real.
Ejemplo de Aprendizaje supervisado en el precio de la vivienda
Un segundo ejemplo de aprendizaje supervisado es la predicción de precios de viviendas. En este caso, el objetivo es entrenar un modelo de aprendizaje automático para predecir el precio de una casa basado en varias características, como el tamaño de la casa, la ubicación, el número de habitaciones, la antigüedad de la casa, etc.
Recopilación de datos y preprocesamiento
Primero, necesitamos recopilar un conjunto de datos de viviendas vendidas, donde para cada casa vendida conocemos tanto las características de la casa (tamaño, ubicación, número de habitaciones, etc.) como el precio de venta. Este conjunto de datos se usará para entrenar nuestro modelo.
En este caso, las «características» de cada instancia son las diversas propiedades de la casa, y la «etiqueta» es el precio de venta. Como la etiqueta es un número continuo (el precio puede variar de una casa a otra), este es un ejemplo de una tarea de regresión en lugar de una tarea de clasificación.
Entrenamiento del modelo
Una vez que tenemos nuestros datos preprocesados, podemos usarlos para entrenar nuestro modelo. Digamos que elegimos usar un modelo de regresión lineal para este propósito. Durante el entrenamiento, el modelo aprenderá los pesos o coeficientes para cada característica de la casa en función de su correlación con el precio de venta.
Por ejemplo, el modelo puede aprender que el tamaño de la casa tiene un gran impacto en el precio, por lo que asignará un peso más alto a esa característica. Sin embargo, la edad de la casa podría tener un impacto negativo en el precio, por lo que esa característica podría tener un peso negativo.
Evaluación y predicción
Después de que el modelo ha sido entrenado, podemos usarlo para predecir el precio de venta de una casa nueva, que el modelo no ha visto antes. Tomamos las características de la nueva casa, y estas se alimentan al modelo.
El modelo luego utiliza los pesos que aprendió durante el entrenamiento para calcular una predicción del precio de venta. Por ejemplo, multiplicará el tamaño de la casa por el peso correspondiente, hará lo mismo para todas las demás características y luego sumará todos estos valores para obtener la predicción del precio de venta.
Este es otro ejemplo típico de cómo se puede utilizar el aprendizaje supervisado para resolver un problema de regresión en la vida real.
Aprendizaje No Supervisado
En el aprendizaje no supervisado, solo disponemos de las características de entrada y no de las etiquetas de salida. El modelo tiene que encontrar alguna estructura o patrones en los datos de entrada por sí mismo. Los algoritmos de aprendizaje no supervisado a menudo se utilizan para tareas de agrupamiento (clustering), reducción de dimensionalidad y detección de anomalías. Ejemplos de modelos de aprendizaje no supervisado incluyen K-means, DBSCAN, PCA (Análisis de Componentes Principales) y autoencoders.
Veamos algunos ejemplos:
Ejemplo de Aprendizaje no supervisado en análisis de segmentos de clientes
Un buen ejemplo de aprendizaje no supervisado es el análisis de segmentos de clientes o «clustering» en el marketing. Aquí, un algoritmo de aprendizaje automático se utiliza para agrupar a los clientes en diferentes segmentos basándose en sus características, pero sin tener segmentos predefinidos.
Recopilación de datos y preprocesamiento
En primer lugar, necesitamos recoger datos de los clientes. Estos datos podrían incluir información como la edad, el sexo, la ubicación geográfica, el historial de compras, la frecuencia de compras, etc.
Aunque los datos no necesitan ser etiquetados (es decir, no necesitamos saber de antemano a qué segmento pertenece cada cliente), todavía necesitamos procesar los datos para que sean comprensibles para el algoritmo. Por ejemplo, podríamos normalizar los datos para que todas las características estén en la misma escala.
Entrenamiento del modelo
Una vez que tenemos los datos preprocesados, podemos usar un algoritmo de aprendizaje no supervisado para identificar segmentos de clientes. Un algoritmo comúnmente utilizado para esto es el K-means.
El algoritmo K-means comienza con un número predefinido de segmentos (el «K» en «K-means»). Luego, asigna aleatoriamente cada cliente a un segmento y calcula el «centroide» de cada segmento (el promedio de todas las características de los clientes en el segmento). A continuación, reasigna cada cliente al segmento cuyo centroide está más cerca (en términos de una medida de distancia, como la distancia euclidiana). Esto se repite hasta que las asignaciones de los segmentos dejan de cambiar significativamente.
Interpretación de los resultados
Después de que el algoritmo ha terminado, tenemos una asignación de cada cliente a un segmento. Ahora podemos examinar los centroides de cada segmento para entender qué caracteriza a cada segmento.
Por ejemplo, podríamos encontrar que tenemos un segmento de clientes que son principalmente hombres jóvenes que compran con frecuencia, un segmento de clientes que son mujeres de mediana edad que compran con menos frecuencia, y así sucesivamente. Estos segmentos pueden ser útiles para diseñar estrategias de marketing dirigidas.
Ejemplo de Aprendizaje no supervisado en Análisis de Componentes Principales
Otro ejemplo común de aprendizaje no supervisado es el Análisis de Componentes Principales (PCA, por sus siglas en inglés), que se utiliza a menudo para la reducción de la dimensionalidad en los conjuntos de datos.
Consideremos un conjunto de datos de salud, que tiene miles de características para cada paciente, incluyendo edad, peso, altura, niveles de colesterol, niveles de glucosa en sangre, presión arterial y muchos más.
Recopilación de datos y preprocesamiento
Primero, necesitamos recoger estos datos y preprocesarlos para hacerlos aptos para el PCA. Este preprocesamiento podría incluir la normalización de los datos (para que todas las características estén en la misma escala) y el manejo de valores perdidos.
Entrenamiento del modelo
Una vez que tenemos los datos preprocesados, podemos aplicar PCA. El objetivo del PCA es encontrar las «componentes principales» en los datos. Estas son direcciones en el espacio de características que capturan la mayor variabilidad en los datos.
PCA comienza calculando la matriz de covarianza de los datos. Luego, calcula los vectores propios y los valores propios de esta matriz. Los vectores propios corresponden a las componentes principales y los valores propios indican cuánta de la variabilidad total de los datos es capturada por cada componente principal.
Generalmente, seleccionamos las primeras N componentes principales (es decir, aquellas con los valores propios más grandes) y proyectamos los datos originales en estas componentes. Esto nos da una representación de menor dimensión de los datos que todavía captura la mayoría de la variabilidad en los datos.
Interpretación de los resultados
El resultado del PCA es una representación de menor dimensión de los datos. Por ejemplo, podríamos reducir nuestro conjunto de datos de miles de características a sólo unas pocas decenas de componentes principales.
Estas componentes principales pueden ser difíciles de interpretar en términos de las características originales, ya que generalmente son combinaciones de todas las características originales. Sin embargo, son útiles para visualizar los datos, para detectar patrones o agrupaciones en los datos y para alimentar a otros algoritmos de aprendizaje automático que pueden tener problemas para manejar datos de alta dimensión.
Seguiremos hablando del tema en WWWhatsnew
Como hemos explorado en estos ejemplos, tanto el aprendizaje supervisado como el no supervisado ofrecen herramientas poderosas y versátiles para abordar una amplia gama de problemas. Desde la detección de spam y la predicción de precios de viviendas, hasta la segmentación de clientes y la reducción de la dimensionalidad, estas técnicas de aprendizaje automático son fundamentales en nuestra interacción con el mundo digital.
Pero, debemos recordar que estos son sólo la punta del iceberg. La inteligencia artificial y el aprendizaje automático son campos vastos y en constante evolución, y hay mucho más que aprender y descubrir. Otras técnicas, como el aprendizaje por refuerzo, las redes neuronales profundas, y la inteligencia artificial basada en reglas, ofrecen aún más formas de analizar y aprender de los datos.
Entonces, ya sea que estés empezando tu viaje en la inteligencia artificial, o que seas un veterano en busca de actualizar tus habilidades, te animamos a que sigas adelante con tu aprendizaje. La inteligencia artificial está moldeando nuestro mundo de formas increíbles y a un ritmo sin precedentes. Al profundizar en su comprensión, te posicionarás en la vanguardia de este apasionante campo, capaz de aprovechar su potencial para innovar, resolver problemas y hacer descubrimientos.
Así que, permanece curioso, sigue aprendiendo y estar atento a lo que viene. El futuro de la inteligencia artificial es brillante, y estamos emocionados de ver lo que descubrirás a medida que exploras aún más este fascinante mundo.