rel=canonical es un atributo en HTML creado para combatir el contenido duplicado en la web. Lo que hace es indicar a los buscadores (Yahoo!, Bing, Google, etc.,) que, dado un conjunto de páginas de similar contenido, deben prestarle atención solamente a una página específica. Los buscadores lo hacen de forma predeterminada, al ver varias páginas similares (p. e., las generadas por tiendas virtuales al permitir al usuario ordenar por «precio» y por «popularidad» un conjunto de artículos ya que aparece el mismo contenido pero en otro orden) tomarán la más «relevante», así que lo magnífico del atributo rel=canonical es que tú eres el que les dice a cual es la que tienen que ponerle especial atención.
Pues bien, en el Blog oficial para Webmasters de Google comparten algunos consejos sobre lo que no hay que hacer al tratar con este tipo de enlaces:
1. rel=canonical apuntando a la primera de una serie de páginas

Es simple, se tiene un artículo dividido en varias páginas y por creer que se está duplicando contenido se toma como URL canónica a la primera, con lo que automáticamente se estarían ocultando a la vista de los buscadores el contenido de la segunda, la tercera, la cuarta, etc. Ahora bien, si lo que deseas es tratar con contenido paginado de otras maneras podrías documentarte sobre el «View-all» y las etiquetas «rel=prev» y «rel=next».

2. URL absolutas escritas como URL relativas

Una URL absoluta es una del tipo «https://www.ejemplo.com/wp-images/gatos.png» con el sufijo «https://www.». Una URL relativa es una más sencilla que prescinde de tal sufijo para indicar rápidamente archivos en subdirectorios del sitio web, por ejemplo, algo del tipo «wp-images/gatos.png» señalará una búsqueda de la imagen «gatos.png» dentro la carpeta «wp-images». Por consiguiente, al mezclar indiscriminadamente ambos tipos de URL internas, lo único que se hará será crear enlaces erróneos. Como ejemplo, al poner <link rel=canonical href=“ejemplo.com/wp-images/gatos.png” />, se estaría indicando que se trate toda esa cadena como una URL relativa, por lo que el rel=canonical apuntará a la URL errónea https://www.ejemplo.com/ejemplo.com/wp-images/gatos.png

3. Múltiples rel=canonical en una página y/o apuntando a sitios ajenos
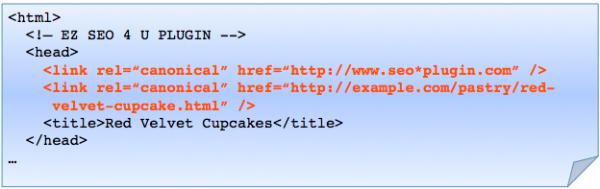
Múltiples declaraciones diferentes del rel=canonical dentro de una misma página puede hacer que se pierdan por completo los beneficios de valerse de enlaces con este atributo. Puede que te esté pasando en este momento y no te des cuenta, poniendo un par de ejemplos, cuando utilizas una plantilla usada por otros usuario y los rel=canonical apuntan a su sitio web en vez de al tuyo, o cuando los plugins SEO agregan enlaces extra automáticamente. Así pues, la única solución es revisar bien el código de las cabeceras para evitar dolores de cabeza por negligencias.

4. Páginas de categorías o landing pages con rel=canonical que apuntan a un artículo destacado
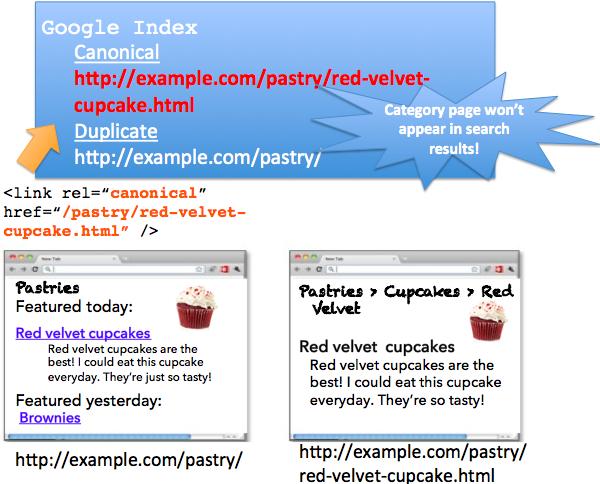
«Por querer hacer más puedes estar haciendo menos». Al pretender evitar el contenido duplicado entre una página de categoría y un artículo destacado creando un enlace rel=canonical que apunte al segundo, lo que realmente puede pasar es que los buscadores prescindan del primero por completo, luego se estaría arriesgando todo un conjunto de artículos a cambio de uno, el que aparece como destacado; Lo mismo sucede con las landing pages. Concluyendo, no hace falta ponerlos.

5. rel=canonical en el cuerpo (<body>) de la página
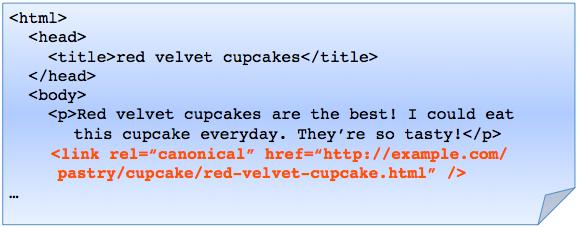
Sobra reafirmar la importancia del rel=canonical para evitar contenido duplicado por lo que debe ser una de las primeras cosas visibles al cargar la página. Esto se logra si y sólo si se pone debidamente el enlace con tal atributo en la cabecera de la página, específicamente dispuesto tan arriba como sea posible dentro de las etiquetas <head> ya que de otra manera, por ejemplo, al ponerlo en el <body> de la página, será ignorado por los buscadores.
