
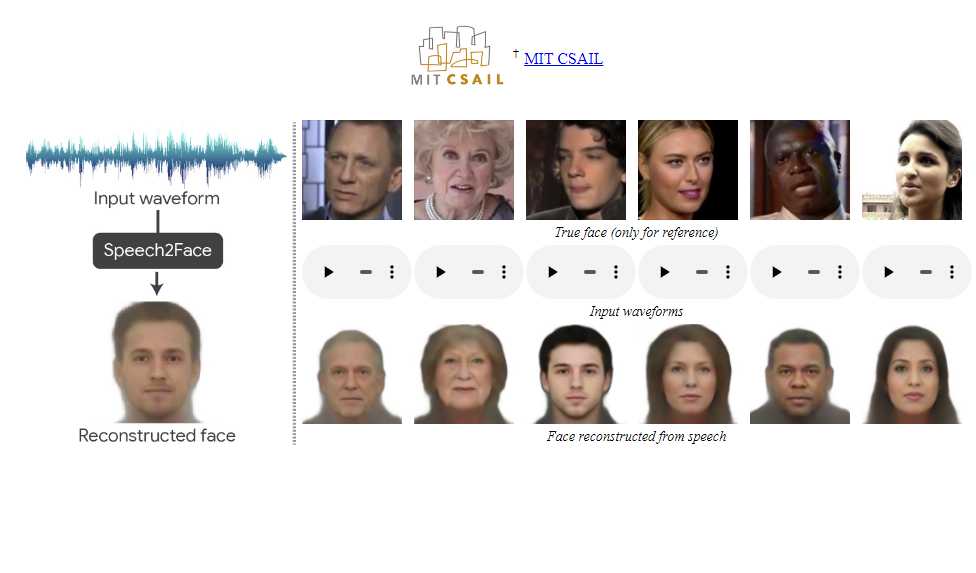
A estas alturas ya no nos vamos a sorprender de lo que puede ser capaz de hacer la Inteligencia Artificial en diferentes ámbitos, incluyendo un modelo de Inteligencia Artificial capaz de recrear visualmente cómo será una persona en función de la forma en la que habla.
Este modelo de Inteligencia Artificial del que os hablamos existe, se llama Speech2Face, y le basta tan sólo tres segundos de un clip de audio para generar la correspondiente recreación visual, aunque la precisión mejorará conforme el clip de audio sea de duración superior.
Dicho modelo fue generado por científicos del Laboratorio de Ciencias de la Computación e Inteligencia Artificial (CSAIL) del MIT, del cual ya escribieron un artículo al respecto, publicado en el año 2019.
Un logro de la IA basándose únicamente en clips de audio
Para conseguir que el algoritmo de IA sea capaz de imaginar al rostro de una persona en base a un fragmento de audio, entrenaron a un modelo utilizando millones de vídeos disponibles tanto en YouTube como en el resto de Internet, en los cuales se muestran a personas hablando.
En el proceso de capacitación del modelo de IA no ha habido participación human alguna. Esto ha permitido que el modelo pueda establecer correlaciones entre la forma del habla con el rostro de las personas, incluyendo aspectos como la edad, género y origen étnico de las personas.
Para mejorar aún más la precisión, los investigadores crearon un decodificador facial que lleva a cabo la reconstrucción de la cara, sin considerar variantes de ese mismo rostro como posiciones e iluminaciones diferentes: en las reconstrucciones aparecen los rostros mirando al frente con una iluminación frontal.
Si bien existen problemas en algunos casos, como cuando se habla con la voz lo suficientemente elevada o más bien baja, generándose confusiones en la recreación, y que en las recreaciones no son todo lo perfecta posibles a las personas hablantes, en este punto queda en cuestión el aspecto de la privacidad.
Los científicos se defienden que este modelo fue generado para fines científicos y que «no puede recuperar la verdadera identidad de una persona por su voz».
Más información/crédito de la imagen: Speech2Face