Google dispone de un sistema capaz de reconocer el texto de imágenes y archivos PDF y transformarlo en un documento digital que pueda ser encontrado y editado. No es el único OCR ( Optical Character Recognition – reconocimiento óptico de caracteres) que existe en Internet, pero sí uno de los más eficaces.
Ayer mismo Google indicó que ya es posible reconocer textos en más de 200 idiomas, una tecnología integrada en Google Drive. Solo tenemos que subir una imagen o PDF a nuestra cuenta y ver cómo se transforma en texto «por arte de magia», solo tenemos que pulsar en la opción del menú (del botón derecho) «abrir como Google Docs».
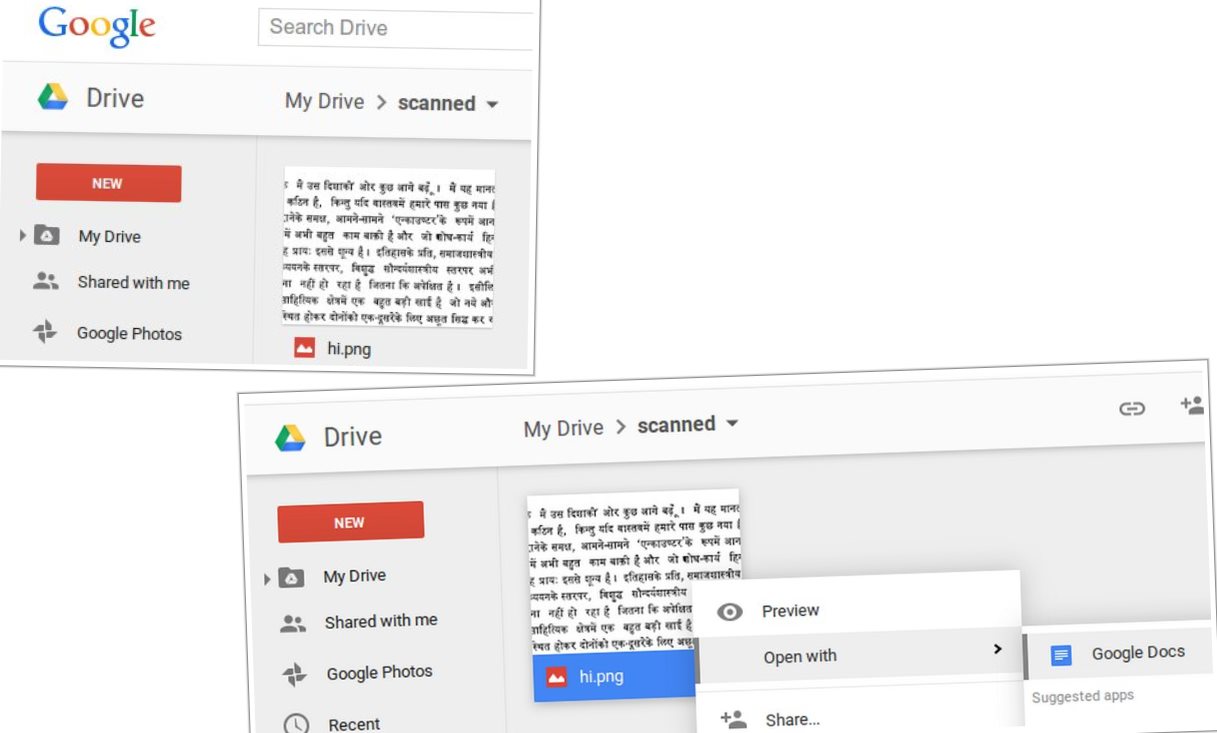

No hay que especificar el idioma del documento, ya que Google hace ese trabajo de forma automática, un trabajo que también es hecho desde la versión android.
Indican en el artículo que este sistema de reconocimiento trabaja perfectamente con documentos bien escaneados, en prácticamente todas las tipografías existentes, aunque ya están trabajando para que sea igual de efectivo en manuscritos y en documentos capturados con cámaras de peor calidad y documentos de menor resolución.