Decirle a un bot que dibuje algo, darle detalles y ver cómo los trazos van tomando forma parece algo del futuro, pero en Microsoft ya tienen la solución prácticamente lista.
Se trata de un programa que escucha lo que decimos y va dibujando poco a poco, generando las figuras hasta obtener resultados como el mostrado en la captura superior.
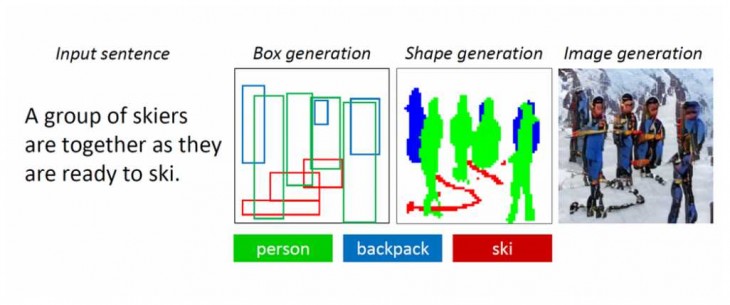
Esta nueva tecnología de IA puede comprender una descripción en lenguaje natural, dibujar un diseño de la imagen, sintetizar la imagen y luego refinar los detalles según el diseño y las palabras individuales proporcionadas. Se trata de un proyecto de colaboración entre Pengchuan Zhang, Qiuyuan Huang y Jianfeng Gao de Microsoft Research AI, Lei Zhang de Microsoft, Xiaodong He de JD AI Research, y Wenbo Li y Siwei Lyu de la Universidad de Albany, SUNY. El proyecto de generación de objetos y escenas se llama ObjGAN.
Para conseguirlo han superado dos problemas:
– Pueden aparecer muchos tipos de objetos en las escenas cotidianas y el robot debería poder entenderlos y dibujarlos a todos. En esta nueva tecnología se usa un conjunto de datos que contiene etiquetas y mapas de segmentación para millones de instancias de objetos en 80 clases, lo que permite al robot aprender el concepto y la apariencia de estos objetos.
– El robot debe entender las relaciones entre múltiples objetos en una escena. Es fácil hacer caras, pájaros y objetos comunes, pero al crear escenas más complejas es necesario que los objetos se relacionen. Este nuevo bot aprendió a generar diseños de objetos a partir de patrones de co-ocurrencia en el conjunto de datos para luego generar una imagen condicionada al diseño generado previamente, ayudando a mejorar el contexto.
Evolucionando la técnica han creado también un sistema de generación de historias, StoryGAN, dando vida a los diseños creados.
La tecnología de generación de texto a imagen puede encontrar aplicaciones prácticas para diseñadores de interiores, creación de películas animadas basadas en guiones y mucho más, aunque de momento las imágenes generadas están aún muy lejos de una foto realista. Los objetos individuales casi siempre revelan defectos, como caras borrosas o autobuses con formas distorsionadas.
Los investigadores compartirán el trabajo con los asistentes de CVPR en Long Beach, y ya tienen el código de código abierto para ObjGAN y StoryGAN en GitHub. Podéis leer más sobre el tema en este artículo.