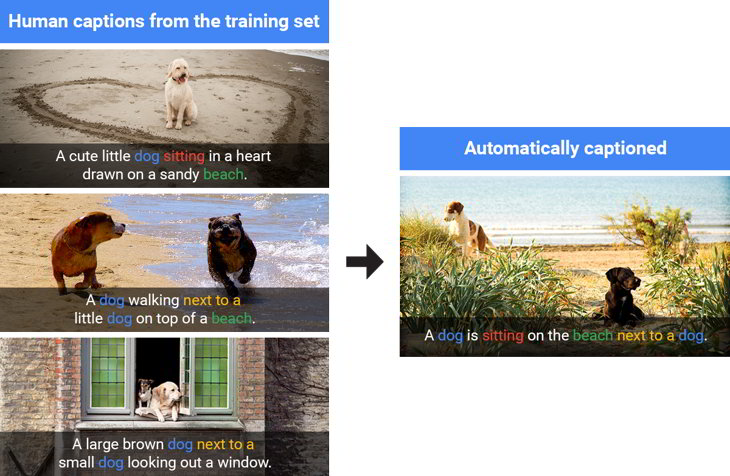
Si reconocer seres y objetos en una imagen es un reto enorme, reconocerlos y además armar un frase para describir lo que está en dicha imagen es un desafío gigante. En Google lo saben y desde 2014 llevan trabajando en un modelo referenciado como Show and Tell que, con técnicas de aprendizaje de máquinas, realiza dicho proceso con brillantes resultados.
Pues bien, dicho modelo se libera ahora al público mundial, esto es, se convierte en open source para que cualquiera pueda adaptarlo a su investigaciones y necesidades. Ya está disponible en TensorFlow acompañado de los diferentes artículos científicos que sustentan su objetivo, funcionamiento técnico, capacidad y detalles para su implementación, entre otras cosas.
Claro, el modelo se ha venido mejorando desde 2014 y aprendiendo cada vez más, tanto que hasta ya ha ganado premios por su eficiencia, y no solo ocupa conjuntos de prueba de imágenes para intentar explicar contenidos -imágenes subtituladas por humanos de las que aprende para aplicarse luego a similares imágenes- sino que trabaja también con imágenes de las que nada sabe.
En cuanto a la calidad de su lenguaje, mencionan que el modelo de Show and Tell, que por cierto es impulsado por un sistema de redes neuronales del tipo encoder-decoder («codifica» la imagen, genera una representación vectorial de ancho fijo y la «decodifica» en una descripción), hasta ha aprendido a escribir en inglés con solo atender a lo aportado por los «subtítulos humanos».
En fin, lo mejor es revisar de inmediato sus páginas web y papers para aprovecharlo en trabajos propios sino es que para aportar a su desarrollo.
Más información: Blog oficial de Google Research | Página en GitHub