Ya hemos comentado en varias ocasiones que el retraso en la carga de las páginas web se traduce en el abandono de los visitantes, sobre todo, en los dispositivos móviles, algo que es significativamente grave en el caso de las tiendas de comercio electrónico.
Ante este escenario, han ido apareciendo diversas soluciones que posibilitan la aceleración de la carga de las páginas web. La última solución hasta la fecha es la aportada por investigadores del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT y de la Universidad de Harvard.
Esta solución, a la que han llamado Polaris, permite la aceleración eficaz de la carga de las páginas web hasta un 34%. Dicha solución será presentada en el Simposio USENIX sobre diseño de sistemas en red e implementación. Básicamente, el funcionamiento de este sistema consiste en la determinación de la superposición de las descargas de los objetos, decreciendo el número de veces que se tiene que hacer uso de la red para obtener los objetos.
En este sentido hay que aclarar que aunque los usuarios obtengamos cada vez más sitios web con apariencia sencilla, los sitios web suelen ser cada vez más complejos en su interior, teniendo cada vez más objetos que cargar, como puedan ser un mayor número de código JavaScript.
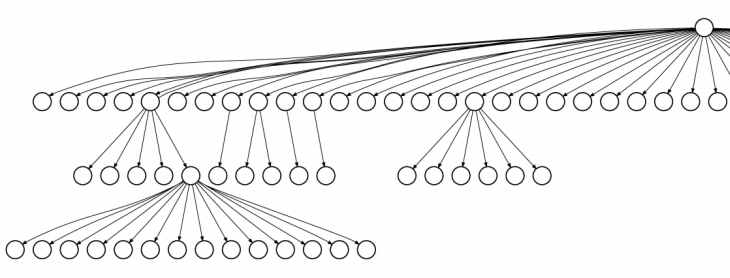
Desde el MIT explican que los navegadores web no conocen las páginas que representarán en pantalla, de modo que tiene que ir a la red de manera continuada en busca de los objetos, que serán evaluados para mostrar sus contenidos en pantalla, aunque parte de estos objetos dependen de otros, conocidos como dependencias, a los que también hay que buscar y evaluar, añadiendo complejidad en su carga.
En este sentido, los navegadores no conocen todas las dependencias, de modo que tendrá que buscar los objetos en orden, teniendo que hacer un mayor número de uso de las redes para buscarlos y descargarlos.
El sistema de Polaris consiste en hacer el seguimiento de las interacciones de los objetos, creando un registro detallado de las dependencias de la página a cargar, lo que determinará la superposición de las descargas.
Desde el MIT señala que si bien ha existido el seguimiento de las dependencias, dicho seguimiento ha estado limitado por los propios navegadores debido a su metodología a la hora de realizar la comparación de las relaciones léxicas, sobre todo, a través del texto de las etiquetas HTML, no pudiendo conocerse las dependencias más relevantes.
Este sistema es potencialmente adecuado para sitios web complejos con multitud de objetos a cargar, como puedan ser complejos códigos JavaScript, algo cada vez más habitual en páginas más modernas.