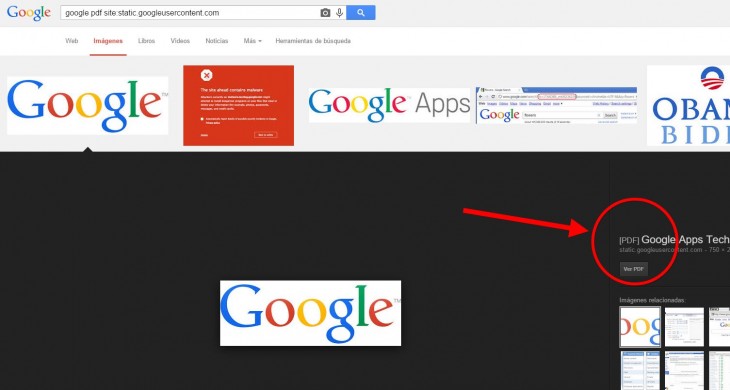
Si publicáis un PDF con imágenes y texto en Internet, Google será capaz de reconocer lo que se ha escrito para ofrecerlo como resultado en su buscador, pero también será capaz de encontrar las imágenes del documento para mostrarlas en su conocido Google Images.
El OCR (sistema de reconocimiento de texto) que usa Google, ya permite encontrar el texto de archivos PDF desde 2008, pero hasta ahora no se había comentado nada sobre lo que ocurre con las imágenes de este tipo de documentos.
Aunque no ha sido Google la fuente de esta noticia (no se ha publicado como nueva funcionalidad en ningún sitio), sí lo han detectado en googlesystem, donde muestran algunos ejemplos con resultados que provienen de archivos pdf.
Técnicamente no representa mucha dificultad, ahora hay que enfocarse en una mejor clasificación de las imágenes encontradas (en Google Photos ya hemos podido comprobar que los avances en este sentido son bastante buenos) y en un mejor sistema de reconocimiento de caracteres manuscritos (algo que no es en absoluto sencillo).
Sobre la licencia de dichas imágenes: es aún más difícil descubrirlo, ya que en teoría la licencia debe ser la misma de la del documento PDF, y muchos de los archivos con este formato publicados en Internet no indican la licencia con la que se comparte, por lo que tened cuidado a la hora de copiarlas para proyectos propios.