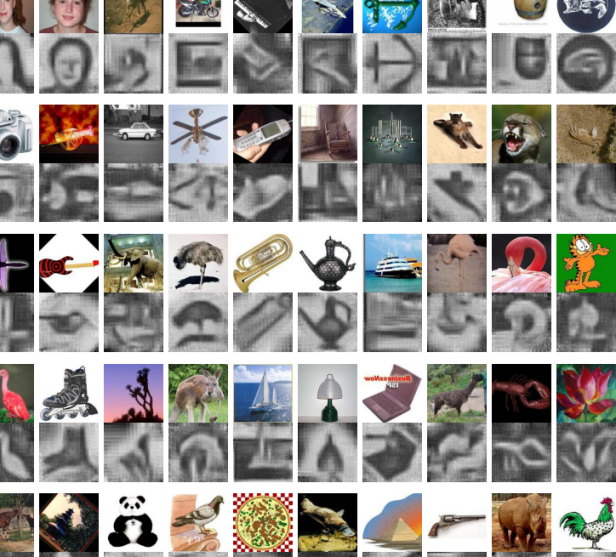
Hace unos días repasamos la novedosa tecnología que incluía el reconocimiento de imágenes con identificación de todos los objetos en ellas y un sistema de subtitulado automático que ofrecía una clara descripción de lo encontrado. Hoy, el protagonista es un trabajo de reconstrucción de imágenes que trabaja de forma inversa, creándolas a partir de una descripción; lo interesante es que, además de los buenos resultados en la generación, a veces se da espacio a la representación de nuevas imágenes como si de creatividad artificial se tratara.
Al buscar en Google, por ejemplo, las cadenas de texto son descompuestas y tratadas con herramientas estadísticas para dar con resultados probabilísticamente similares analizando “bolsas de palabras” de forma no lineal. Tal esencia se ha llevado al mundo de las imágenes para descomponerlas en “palabras visuales”, esto es, cada fragmento en una subdivisión de cada imagen (el cielo en una fotografía, la oreja de una taza, etc.), y luego tratarlas también estadísticamente siendo el trabajo del buscador el comparar entre las múltiples imágenes que coinciden en los fragmentos o secuencias que les componen y presentar las de mayor semejanza.
Entonces, lo usual es analizar una imagen revisando las secuencias que le componen, sin embargo, aunque suene muy complicado por la cantidad de combinaciones posible, también podría pensarse en lo opuesto: “Dado una distribución de palabras visuales, ¿cuál es la imagen original a la que corresponden?”.
Ese es el trabajo científico de investigadores de la Universidad de Tokio quienes han desarrollado un sistema capaz de recrear imágenes partiendo del análisis de las miles de secuencias de un centenar de imágenes considerando, entre otras cosas, su elementos similares, la ubicación específica de los objetos en cada una -por ejemplo, el cielo suele aparecer en la parte superior de una fotografía convencional- y los elementos superpuestos ya que no es tan simple como armar un rompecabezas pues las piezas no tienen necesariamente que encajar.
Combinaciones de probabilidades de aparición y métodos de clasificación para el reconocimiento automático de objetos dentro de imágenes complementan el desarrollo que, como se ve en la imagen que encabeza este artículo, genera resultados sorprendentemente similares a las imágenes originales partiendo de una frase simple cuyas palabras son convertidas en “palabras visuales”; eso cuando no es que se da vida a nuevas y fascinantes imágenes originadas gracias a las mismas limitaciones del trabajo cuyas reconstrucciones o «representaciones de objetos no presentes» podrían entenderse como un resultado de la imaginación computacional.
Artículo científico (PDF, 14 páginas): Image Reconstruction from Bag-of-Visual-Words | Vía: MIT Technology Review